Attention is all you need 这篇笔记将实现Attention is all you need (略有修改),所有的图片均来自该论文。
简介 与卷积序列到序列模型相似,Transformer不使用任何递归。 它还不使用任何卷积层。 相反,模型完全由线性层,注意力机制和规范化组成。
截至2020年1月,Transformers是NLP中的主要架构,用于实现许多任务的最先进成果,并且似乎在不久的将来也是如此。
最受欢迎的Transformer变体是BERT (来自变压器的双向编码器表示),BERT的预训练版本通常用于替换NLP模型中的嵌入层。
本文与论文的主要区别是:
我们使用学习的位置编码,而不是静态的
我们使用具有静态学习率的标准Adam优化器,而不是使用预热和冷却步骤的优化器
我们不使用标签平滑
我们将按照BERT的设置进行所有这些更改,并且大多数Transformer变体都使用类似的设置。
准备数据 与之前的没有太大区别
引入头文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import torchimport torch.nn as nnimport torch.optim as optimimport torchtextfrom torchtext.datasets import Multi30kfrom torchtext.data import Field, BucketIteratorimport matplotlib.pyplot as pltimport matplotlib.ticker as tickerimport spacyimport numpy as npimport randomimport mathimport time
设置随机种子,加载spacy,建立分词函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 SEED = 1234 random.seed(SEED) np.random.seed(SEED) torch.manual_seed(SEED) torch.cuda.manual_seed(SEED) torch.backends.cudnn.deterministic = True spacy_de = spacy.load("en_core_web_sm" ) spacy_en = spacy.load("de_core_news_sm" ) def tokenize_de (text ): """ Tokenizes German text from a string into a list of strings """ return [tok.text for tok in spacy_de.tokenizer(text)] def tokenize_en (text ): """ Tokenizes English text from a string into a list of strings """ return [tok.text for tok in spacy_en.tokenizer(text)]
设置field,数据集,建立词汇表、设备和迭代器等等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 SRC = Field(tokenize = tokenize_de, init_token = '<sos>' , eos_token = '<eos>' , lower = True , batch_first = True ) TRG = Field(tokenize = tokenize_en, init_token = '<sos>' , eos_token = '<eos>' , lower = True , batch_first = True ) train_data, valid_data, test_data = Multi30k.splits(exts = ('.de' , '.en' ), fields = (SRC, TRG)) SRC.build_vocab(train_data, min_freq = 2 ) TRG.build_vocab(train_data, min_freq = 2 ) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) BATCH_SIZE = 128 train_iterator, valid_iterator, test_iterator = BucketIterator.splits( (train_data, valid_data, test_data), batch_size = BATCH_SIZE, device = device)
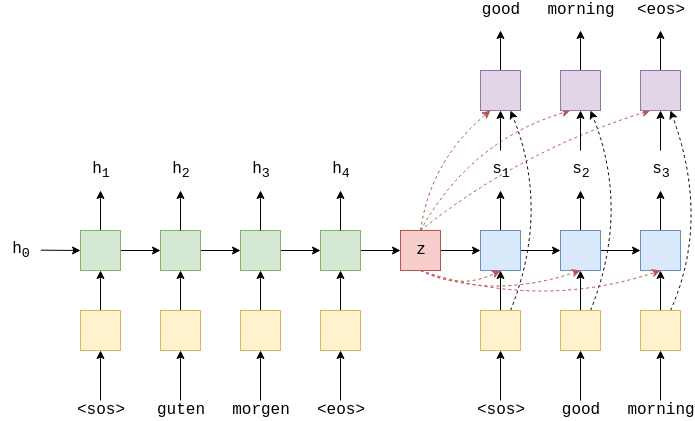
建立模型 接下来,我们将构建模型。 像以前的笔记本一样,它由编码器和解码器组成,编码器将输入/源句子(德语)编码为上下文向量,然后解码器对该上下文向量进行解码以输出我们的输出/目标句子(英语)。
Position-wise Feedforward Layer 输入从hid_dim转换为pf_dim,其中pf_dim通常比hid_dim大很多。 原始的Transformer使用的hid_dim为512,pf_dim为2048。在将ReLU激活函数和dropout转换回hid_dim表示形式之前,先对其进行了应用。
论文中没有解释为什么要用这个层。BERT使用GELU激活,只需将torch.relu切换为F.gelu即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class PositionwiseFeedforwardLayer (nn.Module ): def __init__ (self, hid_dim, pf_dim, dropout ): super.__init__() self.fc1 = nn.Linear(hid_dim, pf_dim) self.fc2 = nn.Linear(pf_dim, hid_dim) self.dropout = nn.Dropout(dropout) def forward (self, x ): x = self.dropout(torch.relu(self.fc1(x))) x = self.fc2(x) return x
Mutli Head Attention Layer Transformer论文的介绍关键、新颖点之一就是多头注意力层。
注意力由query、key、value构成。其中注意力向量由query和key计算获取(通常是softmax的输出,并且位于0-1之间,且总和1为1),然后用来获取value的加权和。
Transformer使用带缩放的点积注意力,其中query和key通过在他们之间取点积进行组合,然后softmax并按$d_k$缩放,最后再乘以value。$d_k$是head的尺寸head_dim。
这和标准点积注意力类似,区别是按$d_k$缩放,论文指出,这个值可以阻止点积过大导致的梯度过小。
但是,按比例缩放的点乘注意力不是简单应用于query、key、value。它不是简单地将query、key、value的hid_dim拆分为$h$个头,而是对所有头并行地计算了扩展的点积注意力,而不是执行单个注意力。这意味着我们不必关注每个注意力而是关注$h$。然后,我们将每个头重新组合成其hid_dim形状,因此每个hid_dim都可能会注意$ h $不同的概念。(读不通)
$ W ^ O $是应用于多头注意层fc末端的线性层。 $ W ^ Q,W ^ K,W ^ V $是线性层fc_q,fc_k和fc_v。
首先我们使用线性层fc_q,fc_k和fc_v计算$ QW ^ Q $,$ KW ^ K $和$ VW ^ V $,以得到Q,K和V。接下来,将 使用.view将查询的hid_dim,键和值转换为n_heads并正确置换它们,以便可以将它们相乘。 然后,我们将Q和K相乘,然后将其乘以head_dim的平方根(按hid_dim // n_heads计算)进行缩放,从而计算出energy(未归一化的注意力)。 然后,我们掩盖了energy,因此我们不必关注序列中不应包含的任何元素,然后应用softmax和dropout。 然后,在将n_head组合在一起之前,我们将注意力集中在value头V上。 最后,我们乘以由fc_o表示的$ W ^ O $。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 class MultiHeadAttentionLayer (nn.Module ): def __init__ (self, hid_dim, n_heads, dropout, device ): super.__init__() assert hid_dim % n_heads == 0 self.hid_dim = hid_dim self.n_heads = n_heads self.head_dim = hid_dim // n_heads self.fc_q = nn.Linear(hid_dim, hid_dim) self.fc_k = nn.Linear(hid_dim, hid_dim) self.fc_v = nn.Linear(hid_dim, hid_dim) self.fc_o = nn.Linear(hid_dim, hid_dim) self.dropout = nn.Dropout(dropout) self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device) def forward (self, query, key, value, mask=None ): batch_size = query.shape[0 ] Q = self.fc_q(query) K = self.fc_k(key) V = self.fc_v(value) Q = Q.view(batch_size, -1 , self.n_heads, self.head_dim).permute(0 , 2 , 1 , 3 ) K = K.view(batch_size, -1 , self.n_heads, self.head_dim).permute(0 , 2 , 1 , 3 ) V = V.view(batch_size, -1 , self.n_heads, self.head_dim).permute(0 , 2 , 1 , 3 ) energy = torch.matmul(Q, K.permute(0 , 1 , 3 , 2 )) / self.scale if mask is not None : energy = energy.masked_fill(mask == 0 , -1e10 ) attention = torch.softmax(energy, dim=-1 ) x = torch.matmul(self.dropout(attention), V) x = x.permute(0 , 2 , 1 , 3 ).contiguous() x = x.view(batch_size, -1 , self.hid_dim) x = self.fc_o(x) return x, attention
Encoder Layer 编码器层是包含编码器所有“meet”的位置。我们首先将源语句及其mask传递到多头注意层,然后对其进行dropout,应用残留连接并将其通过图层归一化层。然后,我们将其传递给位置前馈层,然后再次应用dropout,残余连接,然后对层进行规范化,以获取该层的输出,并将其输出到下一层。层之间不共享参数。
编码器层使用多头注意力层来对源句子施加注意力,即它正在计算并对其自身施加关注,而不是对另一个序列进行关注,因此我们将其称为自我关注。
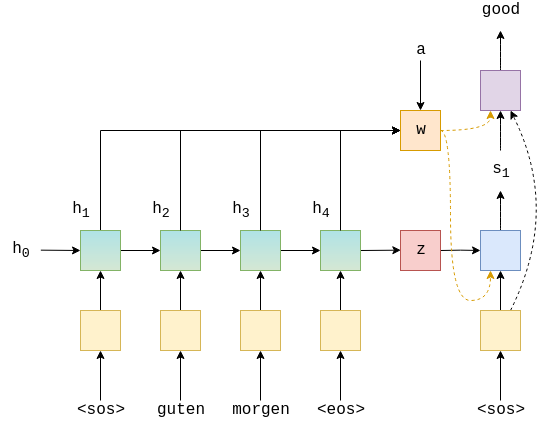
本文将详细介绍有关图层归一化的内容,但要点在于,它可以归一化要素的值,即跨隐藏维度,因此每个要素的平均值为0,标准差为1。这允许神经网络使用诸如“变形金刚”之类的大量层可以更容易地进行训练。
对应图中内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class EncoderLayer (nn.Module ): def __init__ (self, hid_dim, n_heads, pf_dim, dropout, device ): super.__init__() self.self_attn_layer_norm = nn.LayerNorm(hid_dim) self.ff_layer_norm = nn.LayerNorm(hid_dim) self.self_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device) self.positionwise_feedforward = PositionwiseFeedforwardLayer(hid_dim, pf_dim, dropout) self.dropout = nn.Dropout(dropout) def forward (self, src, src_mask ): _src, _ = self.self_attention(src, src, src, src_mask) src = self.self_attn_layer_norm(src + self.dropout(_src)) _src = self.positionwise_feedforward(src) src = self.ff_layer_norm(src + self.dropout(_src)) return src
Encoder 和ConvSeqSeq模型类似,Transformer的编码器不会尝试将整个源句子$X = (x_1, … ,x_n)$压缩为一个上下文向量 $z$,而是生成一系列向量$Z = (z_1, … , z_n)$。因此,如果我们的输入序列是5个令牌,那么我们将有$Z = (z_1, z_2, z_3, z_4, z_5)$。为什么我们称其为上下文向量序列而不是隐藏状态序列?RNN中时间$t$处的隐藏状态仅看到令牌$x_t$及其之前的令牌。但是这里的每个上下文向量都在输入序列内的所有位置看到了所有标记。
首先,token通过标准的嵌入层传递。其实,由于模型没有重复性,模型并不了解序列中token的顺序,我们通过使用称为位置嵌入层的第二个嵌入层来解决此问题。这是一个标准的嵌入层,输入不是令牌而是令牌在序列中的位置,从位置0的第一个token开始,位置嵌入层大小为100,这代表我们的模型最长接受100个token的句子,可以根据实际情况增加。
“Attention is all you need”中的原始transformer无法学习位置嵌入,它使用固定的静止嵌入,而BERT等更新的架构中改为了使用位置嵌入,位置嵌入的更详细信息可以查看这篇文章 。
接下来,将标记和位置嵌入元素逐个相加,获得一个向量,其中包含token以及其在序列中的位置信息。在token嵌入进行求和之前,将其乘以比例因子$\sqrt{d_{model}}$,其中$d_{model}$是隐藏层大小hind_dim。原因是因为这会减少嵌入的方差,并且如果没有此缩放因子,可能很难可靠地训练模型。接下来要dropout。
然后将合并的嵌入内容传递到 $N$编码层获得$Z$,再将其传递到解码器。
源序列的掩码序列src_mask与源句子的大小完全相同(?)。但是当源句子的标记不是标记是,值为1,否则为0.这在编码层用于掩码多头注意力机制,这个机制用于计算和对源句子施加注意力,因此该模型不会注意,这个标记不包含有用信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Encoder (nn.Module ): def __init__ (self, input_dim, hid_dim, n_layers, n_heads, pf_dim, dropout, device, max_length=100 ): super.__init__() self.device = device self.tok_embedding = nn.Embedding(input_dim, hid_dim) self.pos_embedding = nn.Embedding(max_length, hid_dim) self.layers = nn.ModuleList([EncoderLayer(hid_dim, n_heads, pf_dim, dropout, device) for _ in range(n_layers)]) self.dropout = nn.Dropout(dropout) self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device) def forward (self, src, src_mask ): batch_size = src.shape[0 ] src_len = src.shape[1 ] pos = torch.arange(0 , src_len).unsqueeze(0 ).repeat(batch_size, 1 ).to(self.device) src = self.dropout((self.tok_embedding(src) * self.scale) + self.pos_embedding(pos)) for layer in self.layers: src = layer(src, src_mask) return src
Decoder Layer 如前所述,解码器层类似于编码器层,不同之处在于它现在具有两个多头注意层,即self_attention和coder_attention。
就像在编码器中一样,第一个函数通过使用解码器表示(如查询,键和值)来执行自我注意。接下来是辍学,残留连接和图层归一化。该self-attention层使用目标序列掩码trg_mask,以通过注意并行处理目标语句中所有令牌的令牌来防止解码器“作弊”,因为它们要注意当前正在处理的令牌之前的令牌。
第二个是我们实际上是如何将编码后的源语句enc_src馈入解码器的。在该多头注意层中,查询是解码器表示,而键和值是解码器表示。在这里,源掩码src_mask用于防止多头注意层关注源语句中的标记。然后是辍学,残留连接和图层规范化层。
最后,我们将其传递给位置前馈层,以及丢失,残留连接和层归一化的另一个序列。
解码器层没有引入任何新概念,只是使用与编码器相同的一组层,但方式略有不同。
Decoder 解码器用来获取源语句$Z$的编码表示形式,并将其转换为目标语句$\hat{Y}$中的预测的token。然后物品们将$\hat{Y}$与目标句子$Y$中的实际标记进行比较计算损失,用于计算参数的梯度,然后使用优化器按顺序更新权重改善预测。
解码器类似于编码器,但是它具有两个多头注意力层,分别是目标序列上的掩码多头注意力层和用来表示decoder中query、key和value的多头注意力层。
解码器使用位置嵌入,并通过各元素和与缩放后的嵌入目标标记合并,然后dropout。同样,位置编码最大长度为100。
然后将合并的嵌入以及编码器源句子enc_src以及源mask和目标mask传递到$N$解码器层。编码器中的层数不等于解码器中的层数。
然后将$N^{th}$层之后的解码器表示形式通过线性层fc_out。
除了使用源mask之外还使用了目标的mask。 这将在封装编码器和解码器的Seq2Seq模型中进一步说明,但是要点是,它执行与卷积序列到序列模型中的解码器填充类似的操作。 当我们同时并行处理所有目标令牌时,我们需要一种方法,只需简单地“查看”目标序列中的下一个令牌是什么并输出,就可以阻止解码器“作弊”。
我们的解码器层还输出归一化的关注值,因此我们以后可以绘制它们以查看模型实际关注的内容。
Seq2Seq 最后实现Seq2seq,封装了编码器和解码器,并处理了mask。
通过检查源序列在哪里不等于来创建源掩码。令牌不是令牌时为1,反之为0。 然后将其解压,以便在将遮罩应用于energy时可以正确广播,该遮罩的形状为[批处理大小,n个头,seq len,seq len]。
目标序列的掩码复杂一些。 首先,我们为令牌创建掩码,就像为源掩码创建掩码一样。 接下来,我们使用torch.tril创建一个“后续”掩码trg_sub_mask。 这将创建一个对角矩阵,其中对角线上方的元素将为零,对角线下方的元素将被设置为任何输入张量。 在这种情况下,输入张量将是一个填充有张量的张量。 因此,这意味着我们的trg_sub_mask将如下所示(对于具有5个令牌的目标):
这个矩阵表示允许每个目标标记(行)查看的内容(列)。 第一个目标令牌的掩码为[1、0、0、0、0],这意味着它只能查看第一个目标令牌。 第二个目标令牌的掩码为[1、1、0、0、0],这意味着它可以同时查看第一个和第二个目标令牌。
然后,将“后续”掩码与填充掩码进行逻辑和处理,这将两个掩码组合在一起,从而确保后续令牌和填充令牌都不会受到关注。 例如,如果最后两个标记是标记,则掩码将如下所示:
创建掩码之后,它们与编码器和解码器以及源和目标句子一起使用,以获取我们预测的目标句子,输出以及解码器对源序列的关注。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class Seq2Seq (nn.Module ): def __init__ (self, encoder, decoder, src_pad_idx, trg_pad_idx, device ): super().__init__() self.encoder = encoder self.decoder = decoder self.src_pad_idx = src_pad_idx self.trg_pad_idx = trg_pad_idx self.device = device def make_src_mask (self, src ): src_mask = (src != self.src_pad_idx).unsqueeze(1 ).unsqueeze(2 ) return src_mask def make_trg_mask (self, trg ): trg_pad_mask = (trg != self.trg_pad_idx).unsqueeze(1 ).unsqueeze(2 ) trg_len = trg.shape[1 ] trg_sub_mask = torch.tril(torch.ones((trg_len, trg_len), device=self.device)).bool() trg_mask = trg_pad_mask & trg_sub_mask return trg_mask def forward (self, src, trg ): src_mask = self.make_src_mask(src) trg_mask = self.make_trg_mask(trg) enc_src = self.encoder(src, src_mask) output, attention = self.decoder(trg, enc_src, trg_mask, src_mask) return output, attention
Training the seq2seq model 定义参数和模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 INPUT_DIM = len(SRC.vocab) OUTPUT_DIM = len(TRG.vocab) HID_DIM = 256 ENC_LAYERS = 3 DEC_LAYERS = 3 ENC_HEADS = 8 DEC_HEADS = 8 ENC_PF_DIM = 512 DEC_PF_DIM = 512 ENC_DROPOUT = 0.1 DEC_DROPOUT = 0.1 enc = Encoder(INPUT_DIM, HID_DIM, ENC_LAYERS, ENC_HEADS, ENC_PF_DIM, ENC_DROPOUT, device) dec = Decoder(OUTPUT_DIM, HID_DIM, DEC_LAYERS, DEC_HEADS, DEC_PF_DIM, DEC_DROPOUT, device)
定义seq2seq模型
1 2 3 4 SRC_PAD_IDX = SRC.vocab.stoi[SRC.pad_token] TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token] model = Seq2Seq(enc, dec, SRC_PAD_IDX, TRG_PAD_IDX, device).to(device)
计算模型参数
1 2 3 4 def count_parameters (model ): return sum(p.numel() for p in model.parameters() if p.requires_grad) print(f'The model has {count_parameters(model):,} trainable parameters' )
初始化权重
1 2 3 4 def initialize_weights (m ): if hasattr(m, 'weight' ) and m.weight.dim() > 1 : nn.init.xavier_uniform_(m.weight.data) model.apply(initialize_weights);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 LEARNING_RATE = 0.0005 optimizer = torch.optim.Adam(model.parameters(), lr = LEARNING_RATE) criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX) def train (model, iterator, optimizer, criterion, clip ): model.train() epoch_loss = 0 for i, batch in enumerate(iterator): src = batch.src trg = batch.trg optimizer.zero_grad() output, _ = model(src, trg[:, :-1 ]) output_dim = output.shape[-1 ] output = output.contiguous().view(-1 , output_dim) trg = trg[:, 1 :].contiguous().view(-1 ) loss = criterion(output, trg) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), clip) optimizer.step() epoch_loss += loss.item() return epoch_loss / len(iterator) def evaluate (model, iterator, criterion ): model.eval() epoch_loss = 0 with torch.no_grad(): for i, batch in enumerate(iterator): src = batch.src trg = batch.trg output, _ = model(src, trg[:, :-1 ]) output_dim = output.shape[-1 ] output = output.contiguous().view(-1 , output_dim) trg = trg[:, 1 :].contiguous().view(-1 ) loss = criterion(output, trg) epoch_loss += loss.item() return epoch_loss / len(iterator)
结果 没全复制完。。
Epoch: 04 | Time: 0m 10s
未完待续