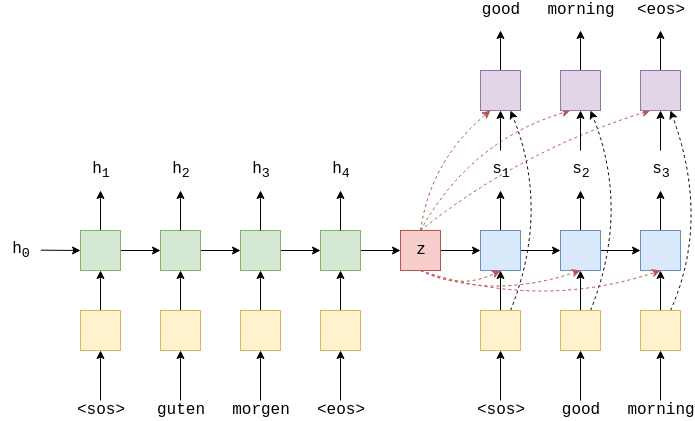
classEncoder(nn.Module): def__init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout): super().__init__() self.embedding = nn.Embedding(input_dim, emb_dim) self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional = True) self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim) self.dropout = nn.Dropout(dropout) defforward(self, src, src_len): #src = [src len, batch size] #src_len = [batch size] embedded = self.dropout(self.embedding(src)) #embedded = [src len, batch size, emb dim] packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, src_len) packed_outputs, hidden = self.rnn(packed_embedded) #packed_outputs is a packed sequence containing all hidden states #hidden is now from the final non-padded element in the batch outputs, _ = nn.utils.rnn.pad_packed_sequence(packed_outputs) #outputs is now a non-packed sequence, all hidden states obtained # when the input is a pad token are all zeros #outputs = [src len, batch size, hid dim * num directions] #hidden = [n layers * num directions, batch size, hid dim] #hidden is stacked [forward_1, backward_1, forward_2, backward_2, ...] #outputs are always from the last layer #hidden [-2, :, : ] is the last of the forwards RNN #hidden [-1, :, : ] is the last of the backwards RNN #initial decoder hidden is final hidden state of the forwards and backwards # encoder RNNs fed through a linear layer hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1))) #outputs = [src len, batch size, enc hid dim * 2] #hidden = [batch size, dec hid dim] return outputs, hidden
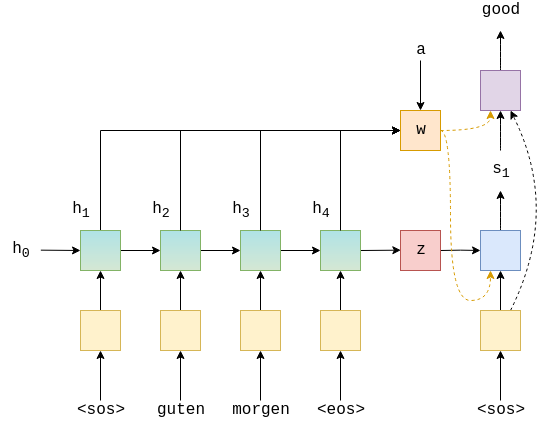
classSeq2Seq(nn.Module): def__init__(self, encoder, decoder, src_pad_idx, device): super().__init__() self.encoder = encoder self.decoder = decoder self.src_pad_idx = src_pad_idx self.device = device defcreate_mask(self, src): mask = (src != self.src_pad_idx).permute(1, 0) return mask defforward(self, src, src_len, trg, teacher_forcing_ratio = 0.5): #src = [src len, batch size] #src_len = [batch size] #trg = [trg len, batch size] #teacher_forcing_ratio is probability to use teacher forcing #e.g. if teacher_forcing_ratio is 0.75 we use teacher forcing 75% of the time batch_size = src.shape[1] trg_len = trg.shape[0] trg_vocab_size = self.decoder.output_dim #tensor to store decoder outputs outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device) #encoder_outputs is all hidden states of the input sequence, back and forwards #hidden is the final forward and backward hidden states, passed through a linear layer encoder_outputs, hidden = self.encoder(src, src_len) #first input to the decoder is the <sos> tokens input = trg[0,:] mask = self.create_mask(src)
#mask = [batch size, src len] for t in range(1, trg_len): #insert input token embedding, previous hidden state, all encoder hidden states # and mask #receive output tensor (predictions) and new hidden state output, hidden, _ = self.decoder(input, hidden, encoder_outputs, mask) #place predictions in a tensor holding predictions for each token outputs[t] = output #decide if we are going to use teacher forcing or not teacher_force = random.random() < teacher_forcing_ratio #get the highest predicted token from our predictions top1 = output.argmax(1) #if teacher forcing, use actual next token as next input #if not, use predicted token input = trg[t] if teacher_force else top1 return outputs
model.eval() if isinstance(sentence, str): nlp = spacy.load('de') tokens = [token.text.lower() for token in nlp(sentence)] else: tokens = [token.lower() for token in sentence]
tokens = [src_field.init_token] + tokens + [src_field.eos_token] src_indexes = [src_field.vocab.stoi[token] for token in tokens] src_tensor = torch.LongTensor(src_indexes).unsqueeze(1).to(device)
src_len = torch.LongTensor([len(src_indexes)]).to(device) with torch.no_grad(): encoder_outputs, hidden = model.encoder(src_tensor, src_len)
if pred_token == trg_field.vocab.stoi[trg_field.eos_token]: break trg_tokens = [trg_field.vocab.itos[i] for i in trg_indexes] return trg_tokens[1:], attentions[:len(trg_tokens)-1]
注意力图展示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
defdisplay_attention(sentence, translation, attention): fig = plt.figure(figsize=(10,10)) ax = fig.add_subplot(111) attention = attention.squeeze(1).cpu().detach().numpy() cax = ax.matshow(attention, cmap='bone') ax.tick_params(labelsize=15) ax.set_xticklabels(['']+['<sos>']+[t.lower() for t in sentence]+['<eos>'], rotation=45) ax.set_yticklabels(['']+translation)