Convolutional Sequence to Sequence Learning 论文地址: Convolutional Sequence to Sequence Learning
Introduction 项目5和之前的项目不同,没有采用循环神经网络,而是采用的常用于图像处理的卷积神经网络。
简单的说,卷积层利用了过滤器。这些过滤器具有宽度属性。如果过滤器的宽度为3,则可以看到3个连续的标记,每个卷积层都有许多的过滤器。每个过滤器将从头到尾在整个序列中滑动,一次查看所有3个连续的标记。这些过滤器中的每一个都将学习从文本中提取不同的功能,然后模型将使用此特征提取的结果作为另一个卷积层的输入。所有这些都可以用于从源句子中提取特征,以将其翻译为目标语言。
Preparing the Data 前面没变。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Ffrom torchtext.datasets import Multi30kfrom torchtext.data import Field, BucketIteratorimport matplotlib.pyplot as pltimport matplotlib.ticker as tickerimport spacyimport numpy as npimport randomimport mathimport timeSEED = 1234 random.seed(SEED) np.random.seed(SEED) torch.manual_seed(SEED) torch.cuda.manual_seed(SEED) torch.backends.cudnn.deterministic = True spacy_de = spacy.load("en_core_web_sm" ) spacy_en = spacy.load("de_core_news_sm" ) def tokenize_de (text ): """ Tokenizes German text from a string into a list of strings """ return [tok.text for tok in spacy_de.tokenizer(text)] def tokenize_en (text ): """ Tokenizes English text from a string into a list of strings """ return [tok.text for tok in spacy_en.tokenizer(text)]
在设置field时稍有区别,默认情况下Pytorch中RNN模型要求序列为[seq_len,batch_size],但是在此项目中使用的CNN中希望batch_size在前面,所以需要设置batch_first=True.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 SRC = Field(tokenize = tokenize_de, init_token = '<sos>' , eos_token = '<eos>' , lower = True , batch_first = True ) TRG = Field(tokenize = tokenize_en, init_token = '<sos>' , eos_token = '<eos>' , lower = True , batch_first = True ) train_data, valid_data, test_data = Multi30k.splits(exts=('.de' , '.en' ), fields=(SRC, TRG)) SRC.build_vocab(train_data, min_freq = 2 ) TRG.build_vocab(train_data, min_freq = 2 ) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) BATCH_SIZE = 128 train_iterator, valid_iterator, test_iterator = BucketIterator.splits( (train_data, valid_data, test_data), batch_size = BATCH_SIZE, device = device)
Building the model 下一步是建立模型,和之前一样,模型由解码器和编码器组成。编码器将源语言中的输入句子编码为上下文向量,解码器解码上下文向量产生目标语言的输出语句。
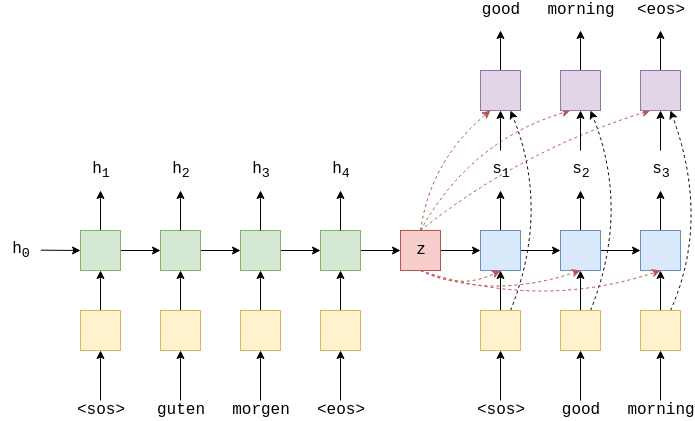
Encoder Encoder 之前的基于RNN的编码器可以将整个输入句子压缩为单个上下文向量$z$.卷积序列到序列模型的编码器则不同,它为输入句子中的的每个token获取两个上下文向量。因此,若输入句子有6个token,则将获得12个上下文向量。
每个token的两个上下文向量——conved向量和combined向量。conved向量是每个token经过几层传递的结果,combined向量是卷积向量和该令牌的嵌入之和。
下图显示输入语句zwei menschen fechten通过编码器的结果。
首先每个token通过嵌入层,但是由于此模型没有循环连接,因此我们对序列中标记的顺序一无所知。为了解决这个问题,我们设置了第二个嵌入层,即位置嵌入层,它的输入不是令牌本身,而是令牌在序列中的位置。
Convolutional Blocks 下面将介绍卷积块如何工作。
下图显示了带有单个过滤器(蓝色)的2个卷积快,该过滤器在序列内的标记上滑动。实际实现中,设置了10个卷积快,每个快中具有1024个过滤器。
首先,填充输入句子。这是因为卷积层将减少输入句子的长度,并且我们希望进入卷积块的句子的长度等于从卷积块中出来的句子的长度。没有填充,从卷积层出来的序列的长度将比进入卷积层的序列的长度短filter_size-1。例如,如果过滤器大小为3,则序列将短2个元素。因此,我们在句子的每一侧都填充了一个填充元素。我们可以通过简单地对奇数大小的过滤器执行(filter_size-1)/ 2来计算每一侧的填充量-在本教程中,我们将不讨论偶数大小的过滤器。
这些过滤器的设计使其输出隐藏尺寸为输入隐藏尺寸的两倍。在计算机视觉术语中,这些隐藏的维度称为渠道-但我们将坚持将其称为隐藏的维度。为什么我们要使卷积滤波器的隐藏维的大小加倍?这是因为我们正在使用一种称为门控线性单元(GLU)的特殊激活函数。 GLU具有包含在激活函数中的选通机制(类似于LSTM和GRU),实际上是隐藏维的一半大小,而激活函数通常会使隐藏维保持相同的大小。
通过GLU激活后,每个令牌的隐藏维数大小与进入卷积块时的大小相同。现在,在通过卷积层之前,将它与自己的向量进行元素求和。
这样就得出了一个卷积块。后续块采用上一个块的输出并执行相同的步骤。每个块都有自己的参数,它们在块之间不共享。最后一个块的输出返回到主编码器-在主编码器中,它通过线性层进行馈送以得到经过转换的输出,然后将元素的嵌入与令牌的总和相加以获得组合的输出。
Encoder Implementation
为了简化,只使用奇数大小的卷积核。
作者使用scale来确保整个网络的方差不会发生显著变化。
位置嵌入初始化为100大小。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 class Encoder (nn.Module ): def __init__ (self, input_dim, emb_dim, hid_dim, n_layers, kernel_size, dropout, device, max_length = 100 ): super().__init__() assert kernel_size % 2 == 1 , "Kernel size must be odd!" self.device = device self.scale = torch.sqrt(torch.FloatTensor([0.5 ])).to(device) self.tok_embedding = nn.Embedding(input_dim, emb_dim) self.pos_embedding = nn.Embedding(max_length, emb_dim) self.emb2hid = nn.Linear(emb_dim, hid_dim) self.hid2emb = nn.Linear(hid_dim, emb_dim) self.convs = nn.ModuleList([nn.Conv1d(in_channels = hid_dim, out_channels = 2 * hid_dim, kernel_size = kernel_size, padding = (kernel_size - 1 ) // 2 ) for _ in range(n_layers)]) self.dropout = nn.Dropout(dropout) def forward (self, src ): batch_size = src.shape[0 ] src_len = src.shape[1 ] pos = torch.arange(0 , src_len).unsqueeze(0 ).repeat(batch_size, 1 ).to(self.device) tok_embedded = self.tok_embedding(src) pos_embedded = self.pos_embedding(pos) embedded = self.dropout(tok_embedded + pos_embedded) conv_input = self.emb2hid(embedded) conv_input = conv_input.permute(0 , 2 , 1 ) for i, conv in enumerate(self.convs): conved = conv(self.dropout(conv_input)) conved = F.glu(conved, dim = 1 ) conved = (conved + conv_input) * self.scale conv_input = conved conved = self.hid2emb(conved.permute(0 , 2 , 1 )) combined = (conved + embedded) * self.scale return conved, combined
Decoder Decoder
解码器接受实际目标句子并预测。这个模型和之前的循环神经网络模型不同,因为它可以并行预测目标句子中的所有token。解码器和编码器类似,对主模型和卷积块做了一些更改。
首先,在经过卷积块和变换之后,嵌入没有连接剩余连接。相反,嵌入被输入到卷积块中,被用作残差链接。
Decoder Convolutional Blocks
首先,填充不同。没有像之前一样在两侧均匀地填充以确保句子长度在整个过程中保持相同,而是仅在句子开头进行填充。
第一个位置的filter尝试利用来预测第二个单词two,如果能够看到tow,则filter可以直接复制而不是学习翻译。
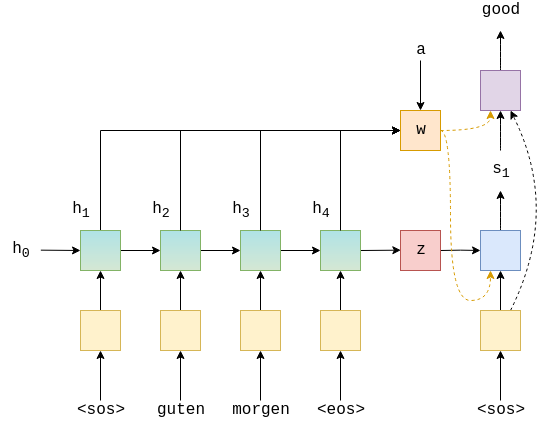
在激活GLU之后残差连接之前,该块使用编码表示和当前的单词嵌入来计算并添加注意力。我们仅显示与最右侧token的连接,但实际上他们已经连接所有token。每个token输入都使用自己的嵌入来进行注意力运算。
过程:首先通过线性层将hid_dim更改为和嵌入尺寸相同来计算注意力。然后通过残差链接对嵌入求和。然后,通过找到与编码对应的token匹配多少对该组合进行标准注意力计算,然后通过对编码的组合获取加权总和来应用该组合,将其投影回到隐藏维度,再应用到初始输入搭配attention层的剩余链接(难理解)
为什么他们先用编码的对等算式计算注意力,然后再用它来计算编码后的组合的加权和?该论文认为,编码的守恒有利于在编码序列上获得更大的上下文,而编码的组合具有有关特定令牌的更多信息,因此对于进行预测更有用
Decoder Impementation 由于我们仅在一侧进行填充,因此允许解码器使用奇数和偶数大小的填充。 同样,scale用于减少整个模型的方差,并且位置嵌入被初始化为“词汇量”为100。
该模型以其正向方法接收编码器表示形式,并将两者都传递给calculate_attention方法,该方法计算并施加注意。 它还会返回实际的attention值,但是我们目前未使用它们。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 class Decoder (nn.Module ): def __init__ (self, output_dim, emb_dim, hid_dim, n_layers, kernel_size, dropout, trg_pad_idx, device, max_length = 100 ): super().__init__() self.kernel_size = kernel_size self.trg_pad_idx = trg_pad_idx self.device = device self.scale = torch.sqrt(torch.FloatTensor([0.5 ])).to(device) self.tok_embedding = nn.Embedding(output_dim, emb_dim) self.pos_embedding = nn.Embedding(max_length, emb_dim) self.emb2hid = nn.Linear(emb_dim, hid_dim) self.hid2emb = nn.Linear(hid_dim, emb_dim) self.attn_hid2emb = nn.Linear(hid_dim, emb_dim) self.attn_emb2hid = nn.Linear(emb_dim, hid_dim) self.fc_out = nn.Linear(emb_dim, output_dim) self.convs = nn.ModuleList([nn.Conv1d(in_channels = hid_dim, out_channels = 2 * hid_dim, kernel_size = kernel_size) for _ in range(n_layers)]) self.dropout = nn.Dropout(dropout) def calculate_attention (self, embedded, conved, encoder_conved, encoder_combined ): conved_emb = self.attn_hid2emb(conved.permute(0 , 2 , 1 )) combined = (conved_emb + embedded) * self.scale energy = torch.matmul(combined, encoder_conved.permute(0 , 2 , 1 )) attention = F.softmax(energy, dim=2 ) attended_encoding = torch.matmul(attention, encoder_combined) attended_encoding = self.attn_emb2hid(attended_encoding) attended_combined = (conved + attended_encoding.permute(0 , 2 , 1 )) * self.scale return attention, attended_combined def forward (self, trg, encoder_conved, encoder_combined ): batch_size = trg.shape[0 ] trg_len = trg.shape[1 ] pos = torch.arange(0 , trg_len).unsqueeze(0 ).repeat(batch_size, 1 ).to(self.device) tok_embedded = self.tok_embedding(trg) pos_embedded = self.pos_embedding(pos) embedded = self.dropout(tok_embedded + pos_embedded) conv_input = self.emb2hid(embedded) conv_input = conv_input.permute(0 , 2 , 1 ) batch_size = conv_input.shape[0 ] hid_dim = conv_input.shape[1 ] for i, conv in enumerate(self.convs): conv_input = self.dropout(conv_input) padding = torch.zeros(batch_size, hid_dim, self.kernel_size - 1 ).fill_(self.trg_pad_idx).to(self.device) padded_conv_input = torch.cat((padding, conv_input), dim = 2 ) conved = conv(padded_conv_input) conved = F.glu(conved, dim = 1 ) attention, conved = self.calculate_attention(embedded, conved, encoder_conved, encoder_combined) conved = (conved + conv_input) * self.scale conv_input = conved conved = self.hid2emb(conved.permute(0 , 2 , 1 )) output = self.fc_out(self.dropout(conved)) return output, attention
Seq2seq 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Seq2Seq (nn.Module ): def __init__ (self, encoder, decoder ): super().__init__() self.encoder = encoder self.decoder = decoder def forward (self, src, trg ): encoder_conved, encoder_combined = self.encoder(src) output, attention = self.decoder(trg, encoder_conved, encoder_combined)
Training the seq2seq model 训练部分和之前的相似,论文得到作者发现较小的卷积核和大量的 层效果更好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 INPUT_DIM = len(SRC.vocab) OUTPUT_DIM = len(TRG.vocab) EMB_DIM = 256 HID_DIM = 512 ENC_LAYERS = 10 DEC_LAYERS = 10 ENC_KERNEL_SIZE = 3 DEC_KERNEL_SIZE = 3 ENC_DROPOUT = 0.25 DEC_DROPOUT = 0.25 TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token] enc = Encoder(INPUT_DIM, EMB_DIM, HID_DIM, ENC_LAYERS, ENC_KERNEL_SIZE, ENC_DROPOUT, device) dec = Decoder(OUTPUT_DIM, EMB_DIM, HID_DIM, DEC_LAYERS, DEC_KERNEL_SIZE, DEC_DROPOUT, TRG_PAD_IDX, device) model = Seq2Seq(enc, dec).to(device)
1 2 3 4 5 6 7 def count_parameters (model ): return sum(p.numel() for p in model.parameters() if p.requires_grad) print(f'The model has {count_parameters(model):,} trainable parameters' ) optimizer = optim.Adam(model.parameters()) criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
下面定义训练函数,其中对序列的处理方式略有不同。对于所有模型,我们都不会将放入解码器。RNN模型中,是通过解码器循环不达到来解决,在此模型中,我们通过将token从序列末尾切开。因此:
$x_i$表示实际目标序列中的元素,然后我们将其输入到模型中获取预测序列,可以预测到token
$y_i$表示预测的目标序列元素,然后我们用原始trg张量计算损失,将切掉,留下token.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def train(model, iterator, optimizer, criterion, clip): model.train() epoch_loss = 0 for i, batch in enumerate(iterator): src = batch.src trg = batch.trg optimizer.zero_grad() output, _ = model(src, trg[:,:-1]) #output = [batch size, trg len - 1, output dim] #trg = [batch size, trg len] output_dim = output.shape[-1] output = output.contiguous().view(-1, output_dim) trg = trg[:,1:].contiguous().view(-1) #output = [batch size * trg len - 1, output dim] #trg = [batch size * trg len - 1] loss = criterion(output, trg) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), clip) optimizer.step() epoch_loss += loss.item() return epoch_loss / len(iterator)
评估
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def evaluate (model, iterator, criterion ): model.eval() epoch_loss = 0 with torch.no_grad(): for i, batch in enumerate(iterator): src = batch.src trg = batch.trg output, _ = model(src, trg[:,:-1 ]) output_dim = output.shape[-1 ] output = output.contiguous().view(-1 , output_dim) trg = trg[:,1 :].contiguous().view(-1 ) loss = criterion(output, trg) epoch_loss += loss.item() return epoch_loss / len(iterator)
1 2 3 4 5 def epoch_time (start_time, end_time ): elapsed_time = end_time - start_time elapsed_mins = int(elapsed_time / 60 ) elapsed_secs = int(elapsed_time - (elapsed_mins * 60 )) return elapsed_mins, elapsed_secs
训练时,设置clip为0.1,否则会梯度爆炸。
尽管我们的参数几乎是基于注意力的RNN模型的两倍,但实际上它花费的时间是标准版本的一半左右,而打包的填充序列版本则花费了大约同一时间。 这是由于所有计算都是使用卷积滤波器并行完成的,而不是依次使用RNN进行的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 if __name__=="__main__" : print(f'The model has {count_parameters(model):,} trainable parameters' ) N_EPOCHS = 10 CLIP = 0.1 best_valid_loss = float('inf' ) for epoch in range(N_EPOCHS): start_time = time.time() train_loss = train(model, train_iterator, optimizer, criterion, CLIP) valid_loss = evaluate(model, valid_iterator, criterion) end_time = time.time() epoch_mins, epoch_secs = epoch_time(start_time, end_time) if valid_loss < best_valid_loss: best_valid_loss = valid_loss torch.save(model.state_dict(), 'tut5-model-3-10.pt' ) print(f'Epoch: {epoch + 1 :02 } | Time: {epoch_mins} m {epoch_secs} s' ) print(f'\tTrain Loss: {train_loss:.3 f} | Train PPL: {math.exp(train_loss):7.3 f} ' ) print(f'\t Val. Loss: {valid_loss:.3 f} | Val. PPL: {math.exp(valid_loss):7.3 f} ' )
Inference 步骤:
分词
添加和
序列化表示
转换为张量并添加batch
输入encoder
创建列表保存输出句子,初始化
在没有达到最大长度时:
将当前的输出句子预测转换为具有batch的张量
将当前输出和两个编码器输出放入解码器
从解码器获取下一个token的预测
将预测添加到句子预测中
如果预测是则中断
将输出语句从索引转换为标记
返回输出语句和注意力
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def translate_sentence (sentence, src_field, trg_field, model, device, max_len = 50 ): model.eval() if isinstance(sentence, str): nlp = spacy.load('de' ) tokens = [token.text.lower() for token in nlp(sentence)] else : tokens = [token.lower() for token in sentence] tokens = [src_field.init_token] + tokens + [src_field.eos_token] src_indexes = [src_field.vocab.stoi[token] for token in tokens] src_tensor = torch.LongTensor(src_indexes).unsqueeze(0 ).to(device) with torch.no_grad(): encoder_conved, encoder_combined = model.encoder(src_tensor) trg_indexes = [trg_field.vocab.stoi[trg_field.init_token]] for i in range(max_len): trg_tensor = torch.LongTensor(trg_indexes).unsqueeze(0 ).to(device) with torch.no_grad(): output, attention = model.decoder(trg_tensor, encoder_conved, encoder_combined) pred_token = output.argmax(2 )[:,-1 ].item() trg_indexes.append(pred_token) if pred_token == trg_field.vocab.stoi[trg_field.eos_token]: break trg_tokens = [trg_field.vocab.itos[i] for i in trg_indexes] return trg_tokens[1 :], attention