Pytorch-seq2seq 学习 0 项目介绍 0.1 预备工作 安装torchtext:
该项目需要使用spacy作为分词工具,我们需要安装其英文版和德文版。
1 2 python -m spacy download en python -m spacy download de
这里出现了连接错误的问题。
1 requests.exceptions.ConnectionError: HTTPSConnectionPool(host='raw.githubusercontent.com', port=443): Max retries exceeded with url: /explosion/spacy-models/master/shortcuts-v2.json (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection object at 0x000002C3A0045390>: Failed to establish a new connection: [Errno 11004] getaddrinfo failed'))
最后选择手动安装,分别在英文 ,德语 下载,然后在命令行运行
1 pip install \你的下载路径\en_core_web_md-2.3.0.tar.gz
特别需要注意的是,model和spcay的版本对应,可以在上面的链接中看到。
数据集下载
0.2 项目介绍
1- [神经网络的序列到序列学习]
第一个教程介绍了带有TorchText seq2seq项目的PyTorch的工作流程。我们将使用编码器-解码器模型介绍seq2seq网络的基础知识,如何在PyTorch中实现这些模型,以及如何使用TorchText在文本处理方面进行所有繁重的工作。该模型本身将基于使用多层LSTM的神经网络 的序列到序列学习 的实现。
2- 使用RNN编解码器学习短语表示以进行统计机器翻译
现在我们已经涵盖了基本的工作流程,本教程将着重于改善我们的结果。基于从上一教程中获得的PyTorch和TorchText的知识,我们将介绍第二个模型,该模型有助于解决编码器-解码器模型所面临的信息压缩问题。该模型将基于使用用于GRU的用于统计机器翻译的RNN编码器/解码器 实现的学习短语表示来 实现。
3- 通过共同学习对齐和翻译的神经机器翻译
接下来,我们通过共同学习对齐和翻译 来实现神经机器翻译,从而 了解注意力。通过允许解码器通过创建作为编码器隐藏状态的加权和的上下文向量来“回顾”输入语句,进一步解决了信息压缩问题。通过注意机制计算该加权和的权重,在该机制中,解码器学习注意输入句子中最相关的词。
4- 压缩填充序列,屏蔽,推论和BLEU ]
在本笔记本中,我们将通过添加打包的填充序列 和masking 来改进以前的模型架构。这是NLP中常用的两种方法。压缩填充序列允许我们仅使用RNN处理输入句子的非填充元素。遮罩用于强制模型忽略某些我们不希望其查看的元素,例如对填充元素的关注。在一起,这些都会给我们带来一点点性能提升。我们还介绍了使用模型进行推理的非常基本的方法,它使我们能够获取要提供给模型的任何句子的翻译,以及如何查看这些翻译在源序列上的注意值。最后,我们展示了如何从翻译中计算BLEU指标。
5- 卷积序列到序列学习
我们最终摆脱了基于RNN的模型,并实现了完全卷积模型。RNN的缺点之一是它们是顺序的。也就是说,在RNN处理一个单词之前,还必须处理所有先前的单词。卷积模型可以完全并行化,从而可以更快地进行训练。我们将实现卷积序列到序列 模型,该模型在编码器和解码器中都使用多个卷积层,并且在它们之间具有关注机制。
6- transformer
继续基于非RNN的模型,我们从Attention Is All You Need 实施了Transformer模型。该模型仅基于注意力机制,并介绍了多头注意力。编码器和解码器由多层组成,每层包括“多头注意”和“位置方式前馈”子层。该模型当前用于许多最新的序列到序列和转移学习任务中。
1 Sequence to Sequence Learning with Neural Networks 在本项目中,我们将使用PyTorch和TorchText构建一个机器学习模型,从一个序列转到另一个序列。这将在德语到英语的翻译中完成,但是模型可以应用于涉及从一个序列到另一个序列的任何问题,例如摘要,即在同一语言中从一个序列到一个较短的序列。论文 模型。
1.1 Introduction 最常见的序列到序列(seq2seq)模型是编码器-解码器模型,它通常使用循环神经网络(RNN)将源(输入)语句编码为单个向量。在本文中,我们将把这个向量称为上下文向量。我们可以认为上下文向量是整个输入语句的抽象表示。然后,这个向量被第二个RNN解码,该RNN通过一次生成一个单词来学习输出目标(输出)句子。
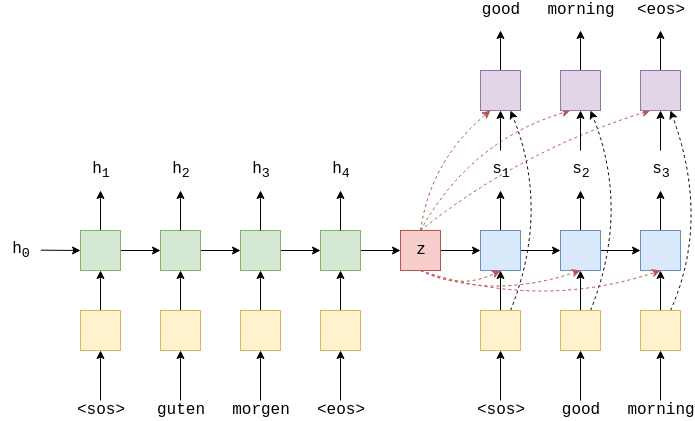
上图是一个翻译的示例,输入语句“guten morgen”通过嵌入层(黄色)后输入到编码层(绿色),在句首和句尾增加作为标签。
encoder的输入不仅是当前单词$e(x_{t}) $,还是上一个时间步的隐藏状态$h_{t-1}$。
encoder输出当前时间步的隐藏状态$h_{t}$
这里的RNN可以为任何递归网络,比如LSTM或者GRU。$,$x_2=guten$,以此类推。初始的隐藏状态$h_0$通常被设置为0或者学习参数。
在decoder中,我们需要将隐藏状态转换为一个实际的单词,因此在每一个时间步中,我们通过$s_t$来预测序列中的下一个词$\hat{y}_t$(通过一个全连接层,图中为紫色)。
注意 :decoder的第一个输入一定是,但是对于后续的输入$y_{t>1}$,我们有时候使用序列中的真值$y_t$,有时候使用解码器预测的值$\hat{y}_{t-1}$。这被称为Teacher forcing,具体内容可以参考链接 标记或生成一定数量的单词。
1.2 准备数据 我们使用pytorch来组建模型,使用torchtext来预处理数据,使用spaCy来分词。
1 2 3 4 5 6 7 8 9 10 11 12 13 import torchimport torch.nn as nnimport torch.optim as optimfrom torchtext.datasets import Multi30kfrom torchtext.data import Field, BucketIteratorimport spacyimport numpy as npimport randomimport mathimport time
设置随机种子
1 2 3 4 5 6 7 SEED = 1234 random.seed(SEED) np.random.seed(SEED) torch.manual_seed(SEED) torch.cuda.manual_seed(SEED) torch.backends.cudnn.deterministic = True
加载spacy模型
1 2 spacy_de = spacy.load("en_core_web_sm" ) spacy_en = spacy.load("de_core_news_sm" )
建立分词函数传递给torchtext
1 2 3 4 5 6 7 8 9 10 11 def tokenize_de (text ): """ Tokenizes German text from a string into a list of strings (tokens) and reverses it """ return [tok.text for tok in spacy_de.tokenizer(text)][::-1 ] def tokenize_en (text ): """ Tokenizes English text from a string into a list of strings (tokens) """ return [tok.text for tok in spacy_en.tokenizer(text)]
建立field
1 2 3 4 5 6 7 8 9 SRC = Field(tokenize = tokenize_de, init_token = '<sos>' , eos_token = '<eos>' , lower = True ) TRG = Field(tokenize = tokenize_en, init_token = '<sos>' , eos_token = '<eos>' , lower = True )
设置训练集、验证机和测试集,exts指向语言。
1 2 3 4 5 train_data, valid_data, test_data = Multi30k.splits(exts = ('.de' , '.en' ),fields = (SRC, TRG)) print(f"Number of training examples: {len(train_data.examples)} " ) print(f"Number of validation examples: {len(valid_data.examples)} " ) print(f"Number of testing examples: {len(test_data.examples)} " ) print(vars(train_data.examples[0 ]))
从训练集中构建词汇表,只构建出现两次及以上的单词,出现一次的标为。
1 2 3 4 SRC.build_vocab(train_data, min_freq=2 ) TRG.build_vocab(train_data, min_freq=2 ) print(f"Unique tokens in source (de) vocabulary: {len(SRC.vocab)} " ) print(f"Unique tokens in target (en) vocabulary: {len(TRG.vocab)} " )
创建迭代器
1 2 3 4 5 6 7 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') BATCH_SIZE = 128 train_iterator,valid_iterator,test_iterator = BucketIterator.splits( (train_data,valid_data,test_data), batch_size=BATCH_SIZE, device=device )
1.3 建立seq2seq模型 1.3.1Encoder 编码器是一个两层的LSTM,第一层的隐藏状态:
第二层的隐藏状态:
我们需要知道的是,LSTM是一种RNN,它不是仅仅处于隐藏状态并且每个时间步返回一个新的隐藏状态,而是每次接收并返回一个单元状态$c_t$
所以我们的上下文向量也改为最终隐藏状态和最终单元状态,即$z^l = (h_T^l, c_T^l)$。
所以encoder图为:
使用的参数有:
input_dim 输入维度,输入的词汇表大小
emb_dim:嵌入层维度
hid_dim:隐藏层和单元层维度
n_layers:LSTM层数
dropout:丢失量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def __init__ (self, input_dim, emb_dim, hid_dim, n_layers, dropout ): super().__init__() self.hid_dim = hid_dim self.n_layers = n_layers self.embedding = nn.Embedding(input_dim, emb_dim) self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout) self.dropout = nn.Dropout(dropout) def forward (self, src ): embedded = self.dropout(self.embedding(src)) outputs, (hidden, cell) = self.rnn(embedded) return hidden, cell
1.3.2Decoder Decoder也是一个两层的LSTM
解码层每个时间步只输出一个token,第一层接受从上一个时间步传来的隐藏和单元状态,然后通过LSTM产生新的隐藏和单元状态,后面的层将会使用前面层的隐藏状态。
最后通过一个全连接层来做预测 $\hat{y}_{t+1} = f(s_t^L)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 class Decoder (nn.Module ): def __init__ (self, output_dim, emb_dim, hid_dim, n_layers, dropout ): super().__init__() self.output_dim = output_dim self.hid_dim = hid_dim self.n_layers = n_layers self.embedding = nn.Embedding(output_dim, emb_dim) self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout) self.fc_out = nn.Linear(hid_dim, output_dim) self.dropout = nn.Dropout(dropout) def forward (self, input, hidden, cell ): input = input.unsqueeze(0 ) embedded = self.dropout(self.embedding(input)) output, (hidden, cell) = self.rnn(embedded, (hidden, cell)) prediction = self.fc_out(output.squeeze(0 )) return prediction, hidden, cell
1.3.3 seq2seq 在实现的最后一部分,我们将实现seq2seq模型。需要处理:
接收输入/源语句
使用编码器生成上下文向量
使用解码器生成预测输出/目标语句
完整模型将如下所示:
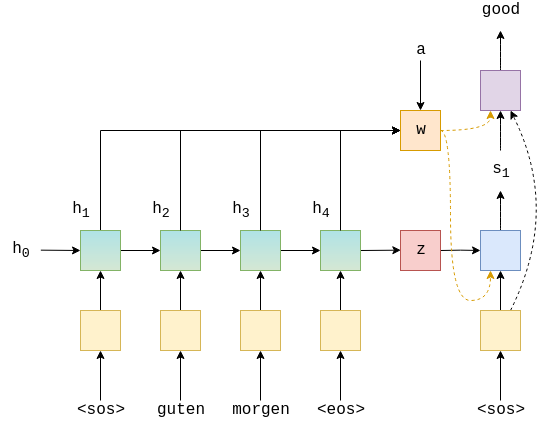
Seq2Seq模型包含一个编码器、解码器和一个device(用于在GPU上放置张量,如果它存在的话)。)标记。由于trg张量已经附加了标记(当我们在trg字段中定义in it_标记时一直如此),我们通过切片得到$y_1$。我们知道我们的目标句子应该有多长(max_len),所以我们循环了很多次。最后一个输入到解码器中的令牌是令牌之前的令牌,令牌永远不会输入到解码器中。
将输入、以前的隐藏和以前的单元状态($y_t,s_{t-1},c_{t-1}$)传递到解码器中
从解码器接收预测、下一个隐藏状态和下一个单元格状态($\hat{y}_{t+1}、s_{t}、c_{t}$)
把我们的预测,$\hat{y}_{t+1}$/输出 放入我们的预测张量,$\hat{y}$/输出
是否要”teacher forcing“
最后我们得到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class Seq2Seq (nn.Module ): def __init__ (self, encoder, decoder, device ): super().__init__() self.encoder = encoder self.decoder = decoder self.device = device assert encoder.hid_dim == decoder.hid_dim, \ "Hidden dimensions of encoder and decoder must be equal!" assert encoder.n_layers == decoder.n_layers, \ "Encoder and decoder must have equal number of layers!" def forward (self, src, trg, teacher_forcing_ratio = 0.5 ): batch_size = trg.shape[1 ] trg_len = trg.shape[0 ] trg_vocab_size = self.decoder.output_dim outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device) hidden, cell = self.encoder(src) input = trg[0 ,:] for t in range(1 , trg_len): output, hidden, cell = self.decoder(input, hidden, cell) outputs[t] = output teacher_force = random.random() < teacher_forcing_ratio top1 = output.argmax(1 ) input = trg[t] if teacher_force else top1 return outputs
1.4 训练 首先,我们将初始化模型。输入和输出维度由词汇表的大小定义。编码器和解码器的嵌入尺寸和损失可以不同,但层的数量和隐藏/单元状态的大小必须相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 INPUT_DIM = len(SRC.vocab) OUTPUT_DIM = len(TRG.vocab) ENC_EMB_DIM = 256 DEC_EMB_DIM = 256 HID_DIM = 512 N_LAYERS = 2 ENC_DROPOUT = 0.5 DEC_DROPOUT = 0.5 enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT) dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT) model = Seq2Seq(enc, dec, device).to(device)
初始化权重
1 2 3 4 5 def init_weights (m ): for name, param in m.named_parameters(): nn.init.uniform_(param.data, -0.08 , 0.08 ) model.apply(init_weights)
计算可训练参数
1 2 3 4 def count_parameters (model ): return sum(p.numel() for p in model.parameters() if p.requires_grad) print(f'The model has {count_parameters(model):,} trainable parameters' )
定义激活函数
1 optimizer = optim.Adam(model.parameters())
定义损失函数
1 2 3 TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token] criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
每次迭代时:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def train (model, iterator, optimizer, criterion, clip ): model.train() epoch_loss = 0 for i, batch in enumerate(iterator): src = batch.src trg = batch.trg optimizer.zero_grad() output = model(src, trg) output_dim = output.shape[-1 ] output = output[1 :].view(-1 , output_dim) trg = trg[1 :].view(-1 ) loss = criterion(output, trg) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), clip) optimizer.step() epoch_loss += loss.item() return epoch_loss / len(iterator)
评估
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def evaluate (model, iterator, criterion ): model.eval() epoch_loss = 0 with torch.no_grad(): for i, batch in enumerate(iterator): src = batch.src trg = batch.trg output = model(src, trg, 0 ) output_dim = output.shape[-1 ] output = output[1 :].view(-1 , output_dim) trg = trg[1 :].view(-1 ) loss = criterion(output, trg) epoch_loss += loss.item() return epoch_loss / len(iterator)
1 2 3 4 5 def epoch_time (start_time, end_time ): elapsed_time = end_time - start_time elapsed_mins = int(elapsed_time / 60 ) elapsed_secs = int(elapsed_time - (elapsed_mins * 60 )) return elapsed_mins, elapsed_secs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 N_EPOCHS = 10 CLIP = 1 best_valid_loss = float('inf' ) for epoch in range(N_EPOCHS): start_time = time.time() train_loss = train(model, train_iterator, optimizer, criterion, CLIP) valid_loss = evaluate(model, valid_iterator, criterion) end_time = time.time() epoch_mins, epoch_secs = epoch_time(start_time, end_time) if valid_loss < best_valid_loss: best_valid_loss = valid_loss torch.save(model.state_dict(), 'tut1-model.pt' ) print(f'Epoch: {epoch+1 :02 } | Time: {epoch_mins} m {epoch_secs} s' ) print(f'\tTrain Loss: {train_loss:.3 f} | Train PPL: {math.exp(train_loss):7.3 f} ' ) print(f'\t Val. Loss: {valid_loss:.3 f} | Val. PPL: {math.exp(valid_loss):7.3 f} ' )
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 The model has 13 ,898 ,757 trainable parameters Epoch: 01 | Time: 0 m 28 s Train Loss: 5.072 | Train PPL: 159.444 Val. Loss: 4.936 | Val. PPL: 139.215 Epoch: 02 | Time: 0 m 27 s Train Loss: 4.571 | Train PPL: 96.614 Val. Loss: 5.450 | Val. PPL: 232.701 Epoch: 03 | Time: 0 m 28 s Train Loss: 4.305 | Train PPL: 74.095 Val. Loss: 4.675 | Val. PPL: 107.252 Epoch: 04 | Time: 0 m 28 s Train Loss: 4.061 | Train PPL: 58.049 Val. Loss: 4.549 | Val. PPL: 94.497 Epoch: 05 | Time: 0 m 28 s Train Loss: 3.881 | Train PPL: 48.457 Val. Loss: 4.483 | Val. PPL: 88.475 Epoch: 06 | Time: 0 m 28 s Train Loss: 3.729 | Train PPL: 41.623 Val. Loss: 4.339 | Val. PPL: 76.655 Epoch: 07 | Time: 0 m 28 s Train Loss: 3.587 | Train PPL: 36.135 Val. Loss: 4.170 | Val. PPL: 64.725 Epoch: 08 | Time: 0 m 27 s Train Loss: 3.438 | Train PPL: 31.120 Val. Loss: 4.079 | Val. PPL: 59.094 Epoch: 09 | Time: 0 m 28 s Train Loss: 3.296 | Train PPL: 27.005 Val. Loss: 3.955 | Val. PPL: 52.205 Epoch: 10 | Time: 0 m 28 s Train Loss: 3.196 | Train PPL: 24.446 Val. Loss: 3.948 | Val. PPL: 51.823 | Test Loss: 3.926 | Test PPL: 50.728 |