Abstract
拼写检查是一个有用的应用程序,它涉及处理嘈杂的人工生成的文本。与英语等其他语言相比,检测和纠正中文拼写错误更具挑战性,因为它包含更多(高达100k)字符。对于中文拼写检查,使用混淆集缩小了搜索空间,使查找更正更容易。然而,大多数(如果不是全部的话)迄今为止使用的混淆集是固定的,因此不包括新的、进化的错误模式。我们提出了一种可扩展的方法,通过利用分层字符嵌入来调整混淆集,以(1)避免手工制作混淆集的需要,以及(2)解决与极少混淆错误相关的稀疏性问题。我们的方法在2014年和2015年中文拼写校正Back-off数据集上建立了拼写错误校正的新SOTA结果。
Introduction
拼写检查是处理书面语言的常见任务,因为拼写检查器是文本编辑器和搜索引擎中不可或缺的组成部分。拼写检查人员必须能够识别错误的单词/字符,并建议候选人进行更正;尽管拼写检查很有用,但由于其特殊性,它在汉语中仍是一个未解决的问题。中文中的大量字符(多达100k)使得纠错具有挑战性,因为有更多的候选字符需要考虑。

Background
中文拼写检查(CSC)中的许多工作使用混淆集(吴等,2010;刘等,2011)。一个字符的混淆集由在语音或形态上与给定字符相似的其他字符组成。例如,一组可能的混淆:無{吾,嫵,舞}。無可能会被误认为混淆集中的任何字符,如無在语音上类似于吾虽然徽标类似于嫵和舞。由于混淆集定义了可能互相替换错误的字符,因此混淆集可用于筛选出特定字符的不太可能的校正候选字符。
虽然混淆集对CSC来说是一种有用的资源,但是构建覆盖不同错误模式的混淆集并不重要。例如,有不同类型的拼写错误,这取决于是手写还是键入。对于后者,拼写错误的种类也取决于使用的输入法(IME)。在像搜狗拼音IME这样基于语音的输入法中,输入一个字符需要输入该字符的发音。在像吴彼·IME这样的基于形态学的输入法中,输入一个字符需要输入组成该字符的一系列子字符单元(形态,偏旁部首)。因此,使用基于语音的输入法经常导致具有相似发音的字符的错误,而使用基于词法的输入法经常导致具有相似词法的字符的错误。不仅是构造涵盖了各种具有挑战性的错误源的混淆集,保持它们的最新也很重要。覆盖率低的混淆集可能会影响拼写检查器的召回,因为它排除了许多可能的纠正候选。有许多工作试图扩展或构建混淆集以增加覆盖率(陈等人,2013;王等,2013;褚、林,2014;谢等,2015)。然而,这些方法涉及人类专家手工制作测量字符之间相似性的函数(陈等人,2013;谢等,2015)或手工制作相似人物聚集的方式(王等,2013;楚和林,2014)。因为涉及到人类专家,所以很难用这些方法来捕捉进化的错误模式。
缺乏带有拼写错误标签的大规模语料库使得过滤成为CSC中的一个重要步骤,因为过滤捕获的许多错误不在训练数据中。此外,它还使得仅使用监督学习来训练精确的CSC模型变得困难。因此,即使CSC仍然可以改进,它可能来自迁移学习或更好的过滤。
Proposed Solution
我们提出了一个CSC模型,该模型使用自适应过滤器代替固定混淆集进行过滤。自适应滤波器使用从使用分级字符嵌入的数据中学习的相似性函数自动构建。由于分级字符嵌入是使用训练数据中的替换错误来训练的,因此我们的模型更适合新的错误模式。我们使用分级的字符嵌入,因为它们捕获了字符之间的语音和标志相似性,这些相似性是导致替换错误的因素。使用分层嵌入还可以更好地过滤很少出现的错误。
考虑到训练数据的缺乏,我们提出的模型还利用了预先训练的掩蔽语言模型(LM) (Devlin等人,2019),该模型显示了最近在迁移学习中的许多成功(Ramachandran等人,2017;Peters等人,2018年;拉德福德等人,2018年;霍华德和鲁德,2018;Devlin等人,2019年)。实验结果表明,自适应滤波模型比基线模型更准确。特别是,我们的方法建立了2014年和2015年中文拼写校正数据集的新结果。
Related works
CSC以前的许多研究都集中在拼写错误的检测和纠正上。N-gram语言建模(LM)已被广泛用于检测错误(常,1995;Yeh等人,2013年;黄等,2014)因为它的简单性。分词是另一种使用各种方法检测错误的方法,例如CRF(王和廖,2014;顾等,2014),基于图的算法(贾等,2013;贾、赵,2014;Xin等,2014;赵等,2017),或隐马尔可夫模型(熊等,2014)。错误检测也被框定为序列标记问题(段等,2019;谢等,2019)。
我们的工作与谢等人(2019)、洪等人(2019)和程等人(2020)的工作最为相似,因为我们还利用转移学习来提升CSC的绩效。然而,我们的过滤步骤不同。而谢等人(2019)的方法使用固定的混淆集进行过滤,洪等人(2019)的过滤可以手动微调,以更好地适应不同的数据。Cheng等人(2020)的过滤是基于由图卷积网络学习的字符相似性。我们的工作使用从训练数据中学习的自适应滤波器来自动估计字符之间的相似性。我们的自适应过滤器利用分层嵌入来利用字符的结构相似性来捕获更多的错误模式。因此,我们的方法可以更好地推广到新的错误,并且可以更好地扩展,因为它不需要手动调整。
Approach
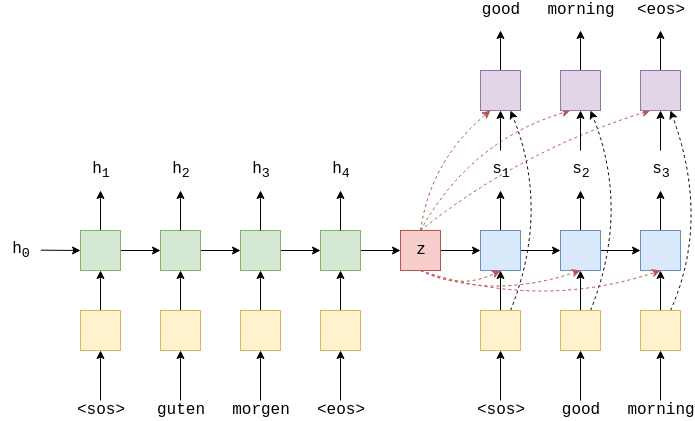
提出的框架如图2所示,由两个部分组成:一个预先训练的掩码LM (BERT)和一个分层嵌入自适应滤波器模型(HeadFilter)。我们利用BERT (Devlin等人,2019)预先训练的上下文嵌入来规避训练数据的缺乏。
掩码LM模型经过训练,可以在所有位置预测正确的字符(图2a)。设Xi、Yi和zi为输入字符,掩码LM对字符的预测分布,以及位置i的预测修正。不过滤:
然而,为了提高校正精度和精确度,在推断过程中对LM的预测进行了过滤(图2b)。过滤模型将在以下章节中介绍。
Adaptable Filter using Hierarchical Embeddings
用混淆集过滤掉不太可能的候选项可以显著提高预测精度(Hsieh等人,2013;杨友和李,2014;张等,2015)。混淆集是一组具有相似词法或发音的字符,因此它们很容易被误认为是另一个。然而,混淆集的质量对系统性能有很大的影响。过时的混淆集可能会遗漏新的错误模式,从而对性能产生负面影响。
我们提出了一个滤波器模型(HeadFilter),它可以使用新训练数据中观察到的误差对进行微调。过滤器模型使用分级字符嵌入,捕捉字符之间的语音和标志相似性(Nguyen等人,2019)。通过应用TreeLSTM (Tai等人,2015;朱等,2015)论人物的树形结构。图3显示了一个字符的树形结构及其分层嵌入(h7)。
一个字符的混淆集可以表示为一个二进制相似向量(图4a中的S),其中每个字符都有一个1。相比之下,由头部过滤器产生的相似性向量(图4c中的bS)具有使用字符结构估计的实值分数。组合所有的混淆集(即连接所有的二进制向量)得到一个相似矩阵(图4b)。
假设字符a和b的分层嵌入是ha hb。使用等式3估计a和b之间的头部过滤器相似性。等式3中的常数β和m分别是比例因子和余量。直观地说,如果两个嵌入向量之间的L2距离(dab)小于余量m,则bS(a,b) in接近1,否则接近0。让我们输入字符的标题过滤器相似性向量。向量表示xi和所有其他N个字符的连接相似性分数(等式4)。
另外,设Si为Xi的混淆集相似向量。过滤后的分布是:
Adaptable Filter Training
本节展示了如何训练分级字符嵌入模型来产生相似性向量的精确估计。设S(a,b)为观察到的两个字符a和b的相似度。
在等式8中,通过最小化对比损失来训练滤波器(Hadsell等人,2006)。最小化这种对比损失迫使相似字符之间的L2距离在边缘m内,并且不同字符之间的L2距离大于边缘m
训练过滤器的例子有两个不同的来源:即来自混淆集的正面和负面例子以及在训练数据中观察到的正面例子。
因此,对于同一混淆集中的所有对(a,b),S(a,b) = 1,否则S(a,b) = 0。此外,S(a,b) = 1也适用于训练数据中的所有错误对(a,b),其中a被误认为b,反之亦然。因为有两个不同的例子来源,所以过滤器分两步训练。首先,训练它使用给定的混淆集模仿过滤行为,将相同混淆集中的字符作为正面示例,不在相同混淆集中的字符作为负面示例。第二,在训练数据中观察到的误差对被进一步添加为正例子,并且使用这个更大的例子集进一步训练滤波器。两步训练的目的是利用训练数据中观察到的额外误差来估计适应的效果(第4.6节)。
为了计算b(a,b)(等式3),我们需要m和β的值。在我们的实验中,我们设置m = 0.4。此外,我们需要设置β,以便当a和b不同时,预测b作为a的校正的概率非常小(小于几率),如等式9所示。
然而,求解所有对(a,b)的方程9是棘手的。因此,我们使用训练数据中的正负例子通过等式10来近似等式9。根据等式10设置β确保平均而言,当a和b不同时,预测b作为a的校正是非常不可能的
Experiments
省略