SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
SpellGCN:将形似字和音似字字纳入中文拼写检查语言模型
1 Abstract
1)汉语拼写检查任务(Chinese splling check)是一项检测并纠正自然语言拼写错误的任务
2)目前大多数方法都有采用混淆集的方式纳入汉字的形似字或者模糊音、同音字等等
3)本文采用图卷积网络(spellgcn)将汉字的相似性信息集成到了模型中
4)在字上建立了一个图,spellgcn将该图映射到一个字符分类器上,这个分类器应用于一个另一个语言特征提取的网络(Bert),使得整个网络可以端到端的训练。
2 Introduction
1)语法错误的产生途径:a.人类打字 b.语音识别 c.光学字符识别。
2)产生原因:字符之间的相似性:语音和视觉相似性。有研究表明,83%的错误来自于语音相似性,49%的来自于视觉相似性。
3)汉语和英语纠错有比较大的区别。汉语是一种由许多不带分界符的象形文字组成的语言,当上下文发生变化时,每个字符的含义都会发生巨大的变化。因此,纠错系统需要识别语义,并对上下文的信息进行必要的修改。
4)过去的研究:过去的研究主要基于生成模型,早期使用语言模型,最近那几年使用seq2seq模型。这些模型为了融合汉字的相似性信息,主要是使用的混淆集。这些方法利用相似度信息来限制候选字符,而不是显式地建立字符之间的关系模型。
5)本文提出的SpellGCN能够捕捉字符之间的语音和视觉相似性,并对字符下先验信息进行了探索。首先分别对应构建了两个相似图,SpellGCN以这两个图为输入,并以相似字符之间信息为每个字符生成矢量表示,然后将这些表示构成字符分类器,用在bert提取的语义表示上。
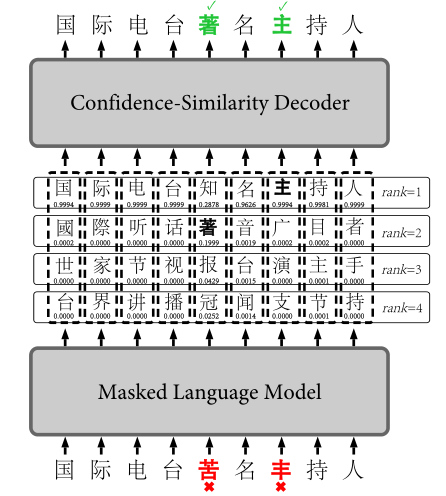
6)从表1我们可以看出,只是用bert可以表达为意思正确但与原义不同的句子,加入SpellGCN后可以生成语义和读音都相同的句子。
7)总结:SpellGCN对bert在纠错任务上有改善。提出了一种新网络,能将汉字相似性整合到语义空间,性能在上个基准数据集上达到了最好效果。

表1 纠正的结果
3 Related Work
1)CSC任务和CGED任务的区别:CSC任务侧重于字符错误的检测和纠正,CGED任务还需要处理插入错误和删除错误。(涨姿势)
2)总结早期:使用无监督语言模型处理CSC,通过评估短语或者句子的复杂程度来检测或者纠正错误。
问题:无法对输入句子进行处理(没有理解到,原文:However, these models were unable to condition the correction on the input sentence.)
解决这个问题:几种不同的序列标记方法、多个序列到序列模型、bert
3)最近大家注意到了提取字符相似性这一外部信息,以前的方法主要是模糊集,相似性信息主要用于选择候选字符,并没有建模字符之间的关系。
4)GCN已经被应用在建模多个任务的关系或多标签任务的标签关系上。
3.Approach
本节主要介绍CSC任务的方法,详细介绍SpellGCN及其应用。
3.1 Problem Formulation
输入:
输出:
建模和最大化条件概率:)
3.2 Motivations
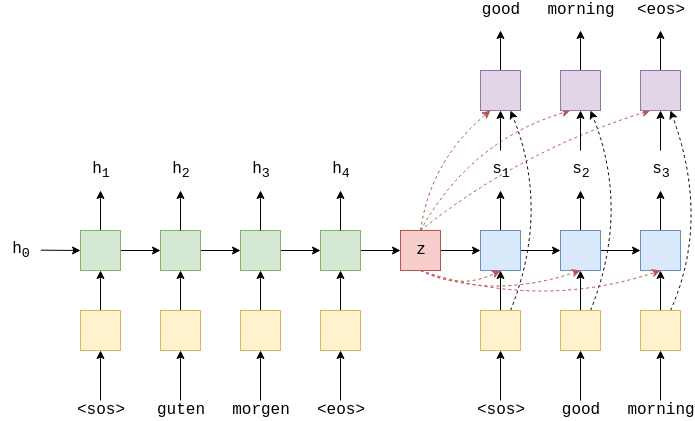
1)整体的框架如图1所示,它由两部分组成,即字符表示提取器和SpellGCN。提取器为每个字符派生一个表示向量。在提取器的右边,SpellGCN用于模拟字符之间的相互依赖关系并输出包含交互后相似字符信息的目标向量。
图1 SpellGCN框架图
2)从表1可以看出仅使用bert不能准确修改句子,过去主要将相似性信息用在潜在字符的选择上,本文试图将语义空间和符号空间(语音和视觉相似性知识)融合在一起。因此,作者采用图神经网络来注入相似性知识,基本思想是:通过汇总相似字符之间的信息来更新表示信息(update the representations by aggregating the information between similar characters)。
3)使用GCN的原因:因为图中有约5000汉字,所以更适用于轻量级的GCN
3.3 Structure of SpellGCN
1)SpellGCN由两个图构建:和,分别对应音似字图和形似字图。
2)每个图由一个大小为的二进制邻接矩阵构成。代表字符个数,第个字符和第个字符的边表示对是否存在于模糊集中。
3)SpellGCN的目标是通过定义的卷积运算将第层的输入节点嵌入映射为新的表示形式,其中是字符嵌入维数。映射函数包含:图卷积运算和图注意力运算。
3.3.1 Graph Convolution Operation
1)图卷积运算可以从相邻字符中吸收信息,其公式如下:
其中,是可训练矩阵,是矩阵的规范化版本。
2)使用BERT作为字符嵌入的初始节点特征,并在卷积之后省略了非线性函数。
3)由于采用BERT作为字符特征抽取器,它有自己的学习语义空间,所以从方程中去掉了激活函数,以保持导出的表示与原始空间相同,而不是完全不同的空间。在实验中,使用非线性激活如ReLU是无效的,会导致性能下降。
3.3.2 Attentive Graph Combination Operation
1)图卷积运算处理的是单个图,为了将两个图结合起来,使用了注意力机制。
2)对于每一个字符,采用了以下的组合操作:
其中,_%7Bi%7D)是图k的第i行的卷积表示,是图k第i个字符权重的标量表示,计算方式如下:
其中是跨层的可学习向量,是控制注意权重平滑度的超参数,实验表明是注意力机制的关键
3.3.3 Accumulated Output
1)经过图卷积和注意力后,我们得到第层的表示:。
2)为了保持提取器的原始语义,将先前各层的所有输出累积为输出:
3)通过这种方式,SpellGCN能够专注于获取字符相似性的知识,将语义推理的责任留给提取器。希望每个层都能学会为特定的跃点聚合信息。在实验过程中,排除H0后模型失效。
3.4 SpellGCN for Chinese Spelling Check
本节介绍如何将SpellGCN应用于CSC任务
3.4.1 Similarity Graphs from Confusion Set
本文的相似图是根据一个已知的混淆集构成的,该混淆集将相似字符分为五类:1)相似的形状,(2)相同的发音和相同的音调,(3)相同的发音和不同的音调,(4)相似的发音和相同的音调,(5) 发音相似,语调不同。
3.4.2 Character Representation by Extractor
实验采用了BERT作为字符特征提取模型。以X为输入,以最后一层的输出为V,采用12层、12个隐藏尺寸为7682的自聚焦头的base版本进行实验。
3.4.3 SpellGCN as Character Classifier
1)当给定字符的向量的时,模型通过全连接层来预测目标字符。其权重由SpellGCN的输出计算得到,M是词汇表大小:%3D%5Coperatorname%7Bsoftmax%7D%5Cleft(%5Cmathbf%7BW%7D%20%5Cmathbf%7Bv%7D_%7Bi%7D%5Cright.))
2)SpellGCN的输出向量扮演着分类器的角色,使用其最后一层的输出来对混淆集中的字符进行分类,而没在混淆集的字符则采用词嵌入作为分类器。
3)若是第i个字符的混淆集索引,W表示为:
E是字符提取的嵌入矩阵,简而言之,如果字符在混淆集则使用SpellGCN嵌入,否则使用BERT嵌入。目标是最大化目标支付的对数概率:)
3.5 Prediction Inference
CSC任务由检测和校正两个子任务组成。以前的工作分别使用了两个模型来完成这些子任务。在本文中,作者简单地使用具有最大概率)的字符作为校正任务的预测。通过检测预测是否与目标字符匹配来实现检测。
4 Experiments
表2 实验所用的数据集
4.1 Datasets
1)训练集和测试集如表2所示
2)五个baseline模型:
LMC:该方法利用混淆集替换字符,然后通过N-gram语言模型对修改后的句子进行评价。
SL:该方法提出了一种采用序列标记模型的检测方法。不正确的字符标记为1(否则为0)。
PN:该方法采用一个指针网络来考虑来自混淆集的额外候选对象。
FASpell:该模型采用了一种基于相似性度量的特殊候选选择方法。该度量使用一些经验方法(例如编辑距离)而不是预定义的混淆集进行测量。
BERT:单词嵌入被用作CSC任务的BERT顶部的softmax层。我们使用相同的设置来训练这个模型,即,没有SpellGCN的可比模型。
3)评价指标:假阳率(FTR)、准确率、精确率、F1
表3 实验结果,D,C表示检测和纠正,P,R,F代表预测,召回和F1
表4 和BERT的比较结果 D-A和C-A表示检测准确性和校正准确性
图2 测试结果曲线
4.2 Hyper-parameters
消融实验
1)GCN层数的影响,如图3所示,在第三层F1达到最大。随着GCN层数的增加,相似度图中相邻字符的表示会越来越相似,因为它们都是通过相似度图中相邻字符的表示来计算的(过度平滑)。
图3 字符级C-F的结果
2)注意力组合运算的有效性
注意力运算比池化效果要好,表明每个字符节点的自适应组合是有益的。
表5 注意力组合运算消融实验结果
Case study
表6 结果示例 第二行为bert 第三行为加上了SpellGCN的结果
Character Embedding Visualization
可以看出形成了簇,说明SpellGCN成功将先验知识导入到了嵌入中。
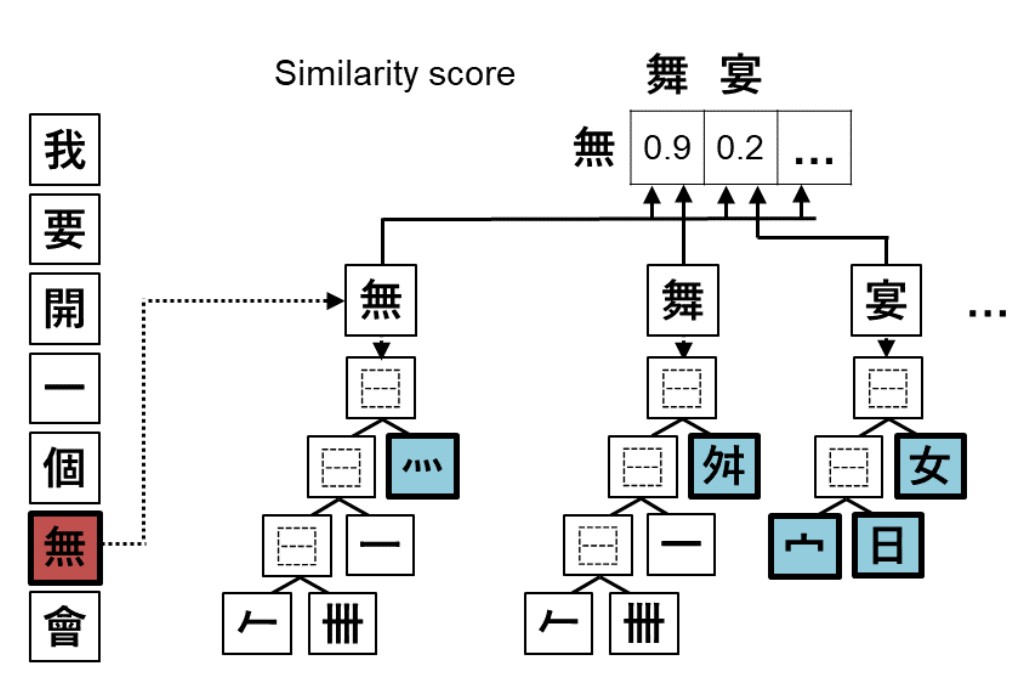
图4 长和祀 语音相似性
图5 长和祀 字符相似性
5 Conclusion
本文为CSC任务提出了SpellGCN,将语音和视觉的相似性结合到语言模型中。实证比较和分析实验结果验证了该方法的有效性。除了CSC之外,SpellGCN还可以推广到其他有特定先验知识的情况,并通过类似地利用特定的相似图来推广到其他语言。通过使用更灵活的提取器,例如Levenshtein Transformer,我们的方法也可以适用于需要插入和删除的GEC任务。