FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm
Abstract
开门见山,第一句话就是提出了一种新的中文拼写检查其——FASpell,并且它基于新范式,这种范式包括一个降噪自动编码器(DAE)和一个解码器。这种范式使得计算更快,且可以适应人或机器产生的简体/繁体中文,有更简单的结构,更强大的检测和纠正能力。之所以有这四个成就,是因为新方式规避了两个瓶颈:1.DAE使用的是无监督预训练掩码语言模型,减少了监督学习需要的数据量;2.解码器有助于消除缺乏灵活性和未充分利用汉字相似性显著特征的混淆集
Introduction
介绍了一些早期工作,尽管大多数研究中拼写错误被简化为替换错误,中文拼写检查仍然是艰巨任务,因为单词之间没有定界符,且缺乏形态上的变化,使得任何汉字的句法和语义解释都高度依赖于其上下文。
Related work and bottlenecks
以前的中文拼写检查模型都有一个通用范式:将每个汉字的一组固定相似字符用作候选项,然后过滤器选择最佳候选项作为给定词汇的替代项。这种设计面临两个主要瓶颈,且很难成功消除其负面影响:
对于严重资源不足的中文拼写检查数据过拟合
中文拼写检查数据资源一直存在资源不足的问题。WANG等人一种自动生成伪拼写检查数据的方法,但是当生成的数据达到40K个句子时,他们的模型精度就不提高了。ZHAO等人使用大量的语法规则来筛选候选对象,效果比FASpell更差。
混淆集在利用字符相似度方面灵活性不足。
汉字相似度的特点非常突出,且和产生错误的原因息息相关。然而混淆集在使用时非常麻烦:
不能灵活地解决一个场景中的混淆字符在另一个场景中可能不会混淆的问题。如表1所示。wang等人还表示,针对机器的混淆字符和针对人类的可能不同。因此,在给定的混淆集中可能不存在正确的替代候选词,这会对召回率造成影响。此外,如果考虑到更多相似特征来保证召回率,可能会降低精确率。
字符相似度利用不足。
由于是通过量化字符相似度的截止阈值来生成混淆集,因此实际上是根据相似度对相似字符进行了不加区分的处理。

Motivation and contributions
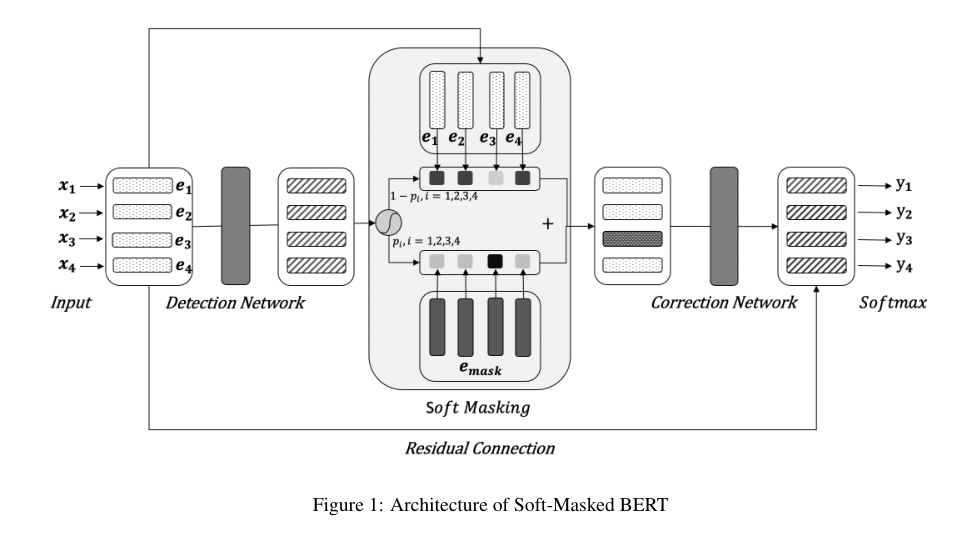
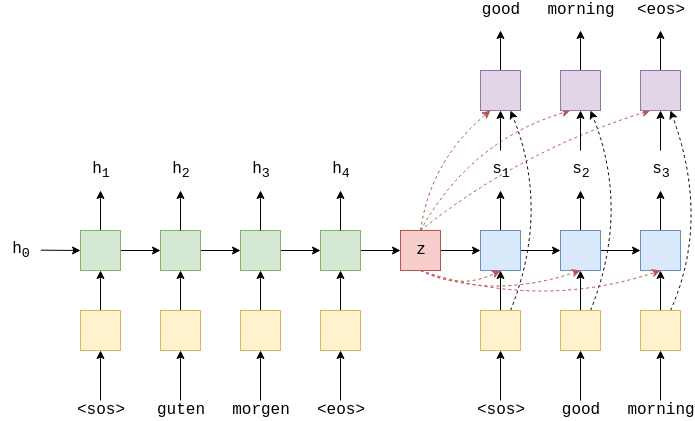
本文目的是改变范式来规避之前提到的两个瓶颈。图一是本文提出的中文拼写检查模型,新范式的最一般形式包括去噪自动编码器(DAE)和解码器。为了证明这是一个新颖的贡献,本文将其与其他两个范式进行了比较:
- 1.与以前中文拼写检查的旧范式相比,DAE解码器的模型也会产生候选,然后过滤候选(通过解码器)。然而候选集是根据上下文动态产生的。如果DAR足够强大,所有上下文合适的候选对象都会被召回,这可以防止使用混淆集导致的不灵活问题。DAE还可以防止过拟合的问题,因为它可以在无监督情况下使用大量自然文本进行训练。此外,解码器可以在不丢失任何信息的情况下利用字符相似性。
- 2.DAE的形式是seq2seq,这使得它在机器翻译,语法检查等任务类似于解编码范式,然而,在接编码器范式中,编码器提取语义信息,解码器生成包含这些信息的文本,相反,在DAE中,DAE根据上下文特征从损失文本中重建文本的候选文本,解码器通过合并其他特征来选择最佳的候选文本。
除此之外,还有两个额外贡献:
- 提出了一种更精确的字符相似度量化方法。
- 提出了一个有效的解码器,尽可能获得最高的准确率和最小的召回伤害的原则过滤候选对象。
Achievements
FASPell:
- Fast。模型计算快,无论是在时间消耗还是在时间复杂度,在过滤方面更快
- Adaptable。适应力强。作者对不同场景下的文本进行了测试:人类文本和机器文本。同时适用于简体和繁体中文,尽管有一个具有挑战性的问题,即繁体中的某些错误用法在简体中文中是正确的。
- Simple。模型是简单的,如图1所示,只有一个掩码语言模型和一个过滤器。此外,该模型只需要一个小的训练集和一组字符的视觉和语音特征,不需要如混淆集的额外数据。
- Powerful。该模型性能强,在检测和矫正水平上达到了与先前先进模型类似的F1。还在OCR数据集上获得了高精度。
FASPell
如图1所示,该模型采用掩码语言模型作为DAE产生候选,置信相似性解码器来过滤候选。实验证明,进行多轮纠错也是有帮助的。
Masked language model
掩码语言模型会猜测序列化句子中[mask]标记的内容。利用MLM作为DAE来检测和纠正中文拼写错误是很直观的,因为它很符合中文拼写检查任务。在BERT的MLM原始训练中,错误是随机的掩码,80%是特殊标记[MASK],10%是词汇表中随机一个token,10%是原始正确的token。在使用随即令牌作为掩码的情况下,模型实际上学会了如何纠正错误字符;在保留原始令牌的情况下,模型实际上学会了如何检测字符是否错误。为了简单起见,FASPell使用了BERT的MLM架构。
但是,仅使用预训练的MLM会引起一个问题,即随机掩码引入的错误可能与拼写检查数据中的实际错误非常不同。因此,作者提出了以下方法来对MLM进行微调:
对于没有错误的文本,按照BERT中的原始训练进行
对于有错误的文本,按以下两种方式创建训练示例:
- 给定一个句子,我们使用其本身来掩盖错误的tokens,并将其目标标签设置为他们对应的正确字符
- 为了防止过拟合,还屏蔽了本身没有错误的token,并将其目标标签设置为自己
两种训练示例的平衡程度大致相同
实验证明,对MLM的预训练在许多下游任务中非常有效,因此有人认为这是FASPell的主要促进因素,但是作者认为不应该归功于MLM。在后文的消融实验中表明,MLM本身只能用作性能很低的中文拼写检查(F1 28.9),解码器利用字符相似性是必不可少的。
Character similarity
错误字符通常在视觉或语音上和正确字符相似。比如OCR产生的错误字符具有视觉相似性。本文将相似性计算基于两个开放数据库:Kanji Database Project和Unihan Database,因为他们为所有的CJK语言和CJK统一表意文字提供了形状和发音表示。
visual similarity
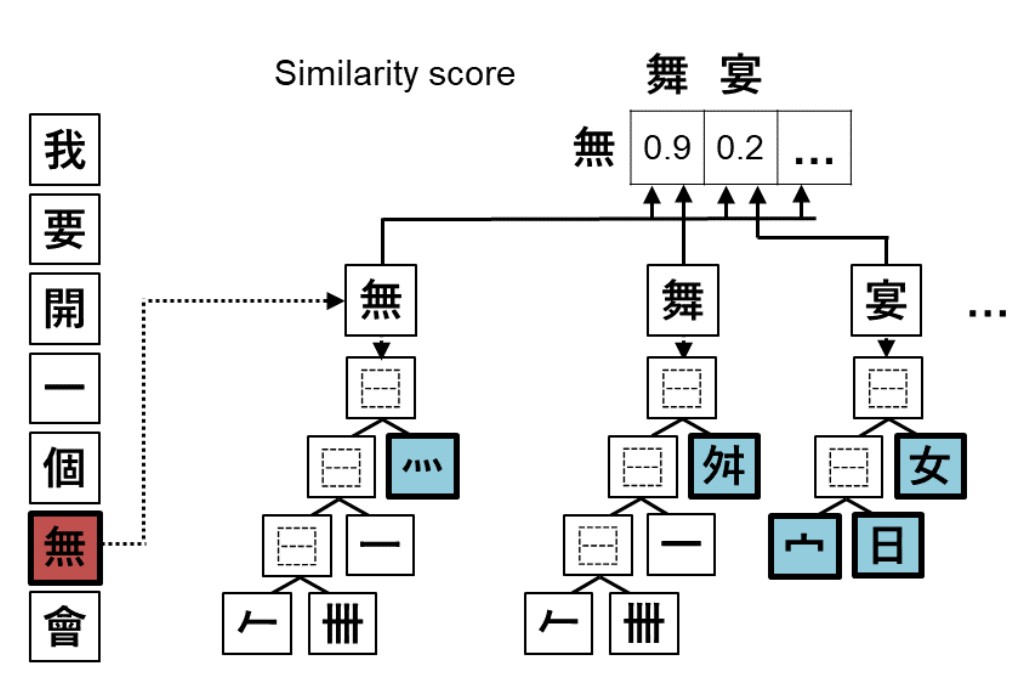
Kanji Database Project使用Unicode标准——表意文中描述序列(IDS)来表示字符形状。
如图2示例,字符的IDS形式上是字符串,实际上是有序树的遍历路径。
在本文的模型中,仅使用字符串形式的IDS,作者将两个字符之间的视觉相似度定义为他们的IDS表示之间的归一化(由于Levenshtein编辑距离的最大值是所讨论的两个字符串的长度的最大值,因此我们只需将其除以最大长度即可对其进行归一化)Levenshtein编辑距离。归一化的原因有两个,首先,为了方便过滤,相似度的范围最好是0到1.其次,如果一对较复杂的字符与一对较不复杂的字符具有相同的编辑距离,则作者希望较复杂的字符的相似性略高于较不复杂的字符相似性,如表2。
本文不适用树形IDS的原因有两个,即使在直观上似乎更有意义,首先,即使目前最先进的算法,树编辑距离的时间复杂度也远大于字符串编辑距离,其次,相关实验表明,使用树和字符串区别不大。
Phonological similarity
具有相同发音的不同汉字非常普遍,任何CJK语言都是这种情况,因此,如果仅使用一种CJK语言来定于字符发音,则字符对的语音相似性将被限制为几个离散值。然而,更连续的语音相似性是可取的,因为它可以使用于过滤候选单词的曲线更平滑。因此,本文利用了Unihan数据库提供的所有CJK语言的字符发音。要计算两个字符的语音相似度,首先计算所有CJK语言中其发音表示之间的标准化负Levenshtein编辑距离,然后取结果的平均值。因此相似度在0-1之间。
Confidence-Similarity Decode
许多先前的模型的候选过滤器都是基于为候选字符的多个特征设置阈值和权重,本文提出了一种方法,该方法在获得尽可能高的进度且召回伤害最小的原则下更有效。由于解码器利用上下文置信度和字符相似度,因此将其成为置信度相似度解码器(CSD),其有效性如下:
首先,考虑最简单的情况,即每个原始字符仅提供一个候选字符。对于与原始字符相同的那些候选,我们不会替代原始字符。对于不同的那些,我们可以绘制一个置信度-相似度散点图。如果将候选者与真实情况进行比较,则该图将类似于图3的图①。我们可以观察到,真正的检测和校正候选者朝着右上角更密集。向左下角提供虚假检测候选者;中间区域中的正确检测和错误校正候选对象。如果绘制一条曲线以过滤掉错误检测的候选对象(图3中的②),然后将其余部分用作替代,我们可以优化字符级精度,而对检测到的字符级召回的危害最小;如果还滤除了正确检测和错误校正候选对象(图3中的图③),我们可以获得相同的校正效果。在FASPell中,我们优化校正性能并使用训练集手动找到过滤曲线,并假设其与相应的测试集保持一致。但是在实践中,我们必须找到两条曲线-每种相似度对应一条曲线,然后与过滤结果取并集。
现在,考虑c> 1个候选者的情况。为了将其简化为上述最简单的情况,我们根据每个原始字符的上下文置信度对候选者进行排名,并将具有相同等级的候选者归入同一组(即总共c个组)。因此,我们可以为每个候选组找到一个如前所述的过滤器。所有c过滤器的组合进一步减轻了召回的危害,因为考虑了更多的候选者。在图1的示例中,有c = 4组候选对象。我们从排名为1的组中获得正确的替换丰→主,从排名为2的组中获得一个正确的替代→苦,而从其他两个组中获取了一个替代。
Experiments and results
本节首先描述实验用到的数据、指标和模型配置,然后展示了FASPell和先前先进模型的性能对比,此外还显示了从OCR结果中收集的数据的性能以证明模型的适应性。然后比较了和其他模型的速度和超参数对模型影响。
Data, metrics and configurations
本文使用了来源于SIGHAN13-15提供的基准数据集和句子等级的准确率、精确率、召回率和F1。此外还从视频中文字幕的OCR结果中收获了4575个句子(简体4516)。表3展示了详细的数据统计信息。
本文采用的掩码语言模型是bert提供的。表4给出了本文主要实验中使用的FASPell的其他配置。对于消融实验使用相同的配置,除了删除CSD意外,本文将排名第一的候选项作为默认输出。需要注意的是,没有微调OCR数据的掩码语言模型,因为在初步实验中发现会损害性能。
Performance
如表6所示,FASPell在检测水平和校正水平均达到了最新的F1性能。它在OCR数据上也达到了相当的精度。OCR数据召回率比较低的原因是即使对于人类来说,许多OCR错误也更难纠正。
表6还显示了FASPell的所有组件均对其有效性能做出了有效贡献,既没有微调又没有CSD的FASPell本质上是预训练的掩码语言模型。进行微调可以提高召回率,因为FASPell可以了解常见错误及其纠正方法。CSD在降低召回伤害的同时提高了精度,因为这是CSD设计时的原理。
Filtering Speed
本文根据每句话的绝对时间消耗来衡量中文拼写检查的过滤速度(常见表5)。我们将FASPell的速度与WANG等人的模型进行了比较。表5清楚地表明FASPell更快。其次,为了将FASPell与尚未报告绝对时间消耗的模型进行比较,本文分析了时间复杂度。FASPell的时间复杂度是$O(scmn+sclogc)$,其中s是句子长度,c是候选项数,mn是计算编辑距离,clogc用于对候选项进行排名。zhang的模型不仅限于编辑距离,因此其模型的时间复杂度还有其他因素。因此,由于本文不采用混淆集,因此他们模型的每个字符的候选数比我们的模型大,因此FASPell更快。(后面都是介绍对比)
Exploring hyper-parameters
首先,仅仅改变表4中的候选者数量,以查看其对性能的影响,如图4所示,当考虑更多候选时,在使精度最大化的同时,还可以调用其他检测和校正,因此,候选增加F1会提高。我们在表4中设置候选数c = 4而不是更大的原因是因为要权衡时间消耗。其次,对表4中的拼写检查轮数执行相同的操作。我们可以在图4中观察到,当轮数为3时,T st14和T st15的校正性能达到峰值。对于T st13和T stocr,该数字分别是1和2。由于FASPell可以在每个回合中实现较高的检测精度,因此有时可以进行更多回合,因此可以在下一回合中检测并纠正上一回合中未发现的错误,而不会错误地检测到过多的非错误。
Conclusion
我们建议使用中文拼写检查工具– FASPell,以达到最先进的性能。它基于DAE解码器范例,仅需要少量的拼写检查数据,并放弃了令人困惑的混淆集概念。以FASPell为例,该范式的每个组件都被证明是有效的。我们在https://github.com/iqiyi/FASPell上公开提供我们的代码和数据。未来的工作可能包括研究DAEdecoder范式是否可用于检测和纠正语法错误或其他不太经常研究的汉语拼写错误类型,例如辩证口语=和插入/删除错误。
本文常提到的比较模型wang是指这篇论文