Spelling Error Correction with Soft-Masked BERT
基于Soft-Masked BERT的拼写纠错
Abstract
拼写错误纠正是一项重要而又具有挑战性的任务,因为一个令人满意的解决方案本质上需要人类水平的语言理解能力。在不失一般性的前提下,本文考虑了汉语拼写错误校正问题。该任务的一种最先进的方法是根据BERT(语言表示模型)从候选字符列表中选择一个字符,在句子的每个位置进行纠正(包括不纠正)。但是,由于BERT没有足够的能力检测每个位置是否有错误,因此该方法的准确性可能是次优的,这显然是由于使用掩码语言建模对其进行预训练的方式造成的。在这项工作中,我们提出了一种新的神经网络来解决上述问题,该网络由基于BERT的错误检测网络和错误校正网络组成,前者通过软掩蔽技术与后者连接。我们使用“ Soft-Masked BERT”的方法是通用的,并且可以用于其他语言检测校正问题。在两个数据集上的实验结果表明,我们提出的方法的性能明显优于baseline,包括仅基于BERT的baseline。
1 Introduction
拼写错误纠正是一项旨在纠正单词和字符级别拼写错误的任务。常常被用在搜索(比如百度知道的你要找的是不是:xxx),光学字符识别(纠错后能提高准确率)和论文得分。
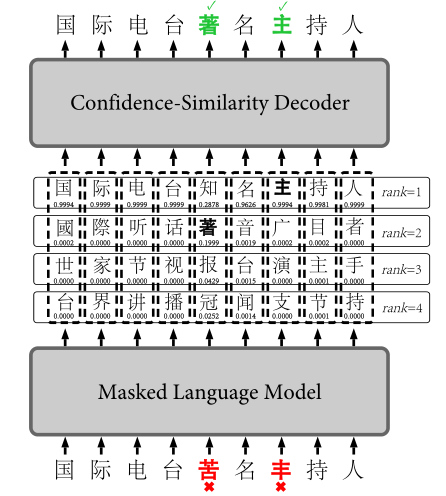
本篇论文考虑的是字符级别的中文拼写错误纠正。一个纠错实例如表1.

第一个例子中,“金子塔”改为“金子塔”需要人类的世界知识(world knowledge)。
第二个例子中,“求胜欲”改为“求生欲”需要根据上下文来推理。
总结了下过去的非BERT方法,重点说了下用指针网络那篇。
目前BERT用于CSC任务的方法:首先用大型未标记数据集对字符级BERT进行预训练,再使用标记数据集微调。标记数据可以通过数据扩充获得,比如使用大的混淆集生成拼写错误。最后,使用该模型根据给定句子每个位置的候选列表获取最可能出现的字符。
这种方法功能强大,因为BERT具有一定的获取知识进行理解的能力。
不过作者进行的实验证明,准确性可以进一步提高。一是模型的错误检测能力不够高,检测到错误才能有更好的机会进行纠正。假设这是因为MLM模型进行预训练导致的,因为MLM模型仅仅掩盖了15%的字符,因此仅仅学习了掩码令牌的分布,并且倾向于选择不进行任何更改。
为了解决这个问题,作者提出了一种叫做SoftMasked-BERT的神经网络,它包含两个网络,基于BERT的检测网络和一个纠正网络。
矫正网络使用的是类似于近似于BERT的方法。检测网络使用的是Bi-GRU网络,可以预测字符在每个位置出现错误的可能性,然后利于该概率对位置上的字符进行软掩膜。
软掩膜是对传统掩膜的一种扩展,当错误概率为1是,两者相同。
软掩膜后将每个位置的软掩膜嵌入输入到矫正网络进行矫正,这种方法可以在端到端联合训练期间,迫使模型在检测网络的帮助下学习正确的上下文以进行错误纠正。
然后进行了实验证明了软掩膜的有效性。
2 Our Approach
2.1 Problem and Motivation
CSC任务可以形式化为:
原序列:$\mathbf{X}=\left\{x_{1}, x_{2}, \ldots, x_{n}\right\}$,目标序列:$\mathbf{Y}=\left\{y_{1}, y_{2}, \ldots, y_{n}\right\}$
两个序列长度相同(不处理删除、插入错误),X中的错误字符在Y中被正确替换。
目前CSC任务的SOTA方法使用了BERT来完成。作者进行的实验表明,如果指定错误字符,该方法性能会提高。但是基于BERT的方法更加倾向于不做修正,作者认为原因是因为在BERT的预训练中,只有15%的字符被掩膜用于预测,从而导致模型不具有足够的错误检测能力。
2.2 Model
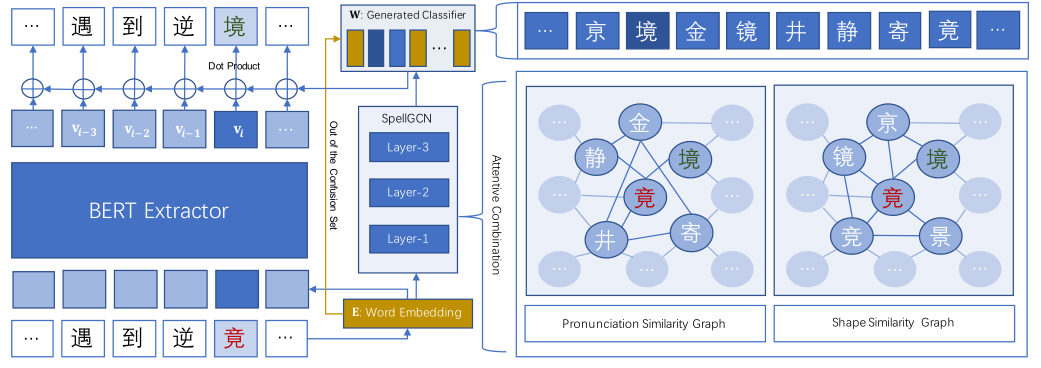
本文提出的Soft-Masked BERT的模型结构如图1所示。
它由基于Bi-GRU的检测网络和基于BERT的纠正网络组成,检测网络预测错误概率,矫正网络预测错误矫正的概率,他们之间通过软掩膜来传递结果。
这种方法首选为输入句子中的每个字符创建输入嵌入,将其输入到检测网络中输入每个字符嵌入的错误概率。之后,计算输入嵌入和[mask]嵌入的加权综合(错误概率加权)。计算出的嵌入以一种“软”的方式掩盖序列中可能的错误,再将软掩膜嵌入序列输入到矫正网络中输出错误矫正的概率。矫正网络是BERT,最终层是所有字符的softmax函数组成。输入嵌入和最后一层嵌入之间还存在着一些链接。
2.3 Detection network
检测网络是一个二进制序列标注模型,输入为嵌入序列$\mathbf{E}=\left\{e_{1}, e_{2}, \ldots, e_{n}\right\}$其中$e_i$是字符$x_i$的嵌入,是字符嵌入,位置嵌入和端嵌入的总和(BERT)。输出是标签$\mathbf{G}=\left\{g_{1}, g_{2}, \ldots, g_{n}\right\}$的序列,其中$g_i$表示第i个字符的标签,1表示字符不正确,0表示字符正确。对于每个字符,有一个概率$p_i$,$p_i$越高,字符不正确可能性越大。
作者的检测网络为双向GRU网络,对于序列中的每个字符,错误$p_i$的概率定义为:
其中,$P_{d}\left(g_{i}=1 | X\right)$表示检测网络给出的条件概率,$\sigma$表示sigmoid函数,$h_{i}^{d}$表示Bi-GRU的隐藏状态,$W_d$和$b_d$是模型的参数。
隐藏状态被定义为:
其中$\overrightarrow{h_{i}^{d}};\overleftarrow{h}_{i}^{d}$代表两个方向串联的GRU隐藏状态。
软掩膜等于以错误概率为权重的输入嵌入和掩膜嵌入的加权总和,软掩膜的第i个字符的嵌入$e_i^{‘}$为
其中,$e_i$是输入嵌入,$e_{mask}$是掩膜嵌入。如果错误可能性很高,软掩膜嵌入就接近于掩膜嵌入,否则接近于输入嵌入。
2.4 Correction Network
矫正网络是基于BERT的序列多分类标记模型。输入时软掩膜嵌入的序$\mathbf{E^{‘}}=\left\{e_{1}^{‘}, e_{2}^{‘}, \ldots, e_{n}^{‘}\right\}$,输出时字符序列$\mathbf{Y}=\left\{y_{1}, y_{2}, \ldots, y_{n}\right\}$
BERT由12个相同的块组成,以整个序列作为输入。每个block包含一个多头部的self-attention操作,随后是一个前馈网络,定义为:
最后一层的隐藏状态表示为$\mathbf{H^{c}}=\left\{h_{1}^{c}, h_{2}^{c}, \ldots, h_{n}^{c}\right\}$
对于序列的每个字符,纠错的概率定义为:$P_{c}\left(y_{i}=j | X\right)=\operatorname{softmax}\left(W h_{i}^{\prime}+b\right)[j]$
其中,$P_{c}\left(y_{i}=j | X\right)$表示表示在候选列表中将字符$x_i$校正为字符$j$的概率,softmax是softmax函数,$h_{i}^{\prime}$是隐藏状态,W和b是参数。隐藏状态$h_{i}^{\prime}$通过与残差连接的线性组合得到:$h_i^{\prime}=h_i^{c}+e_i$
其中$h-i^{c}$是最后一层的隐藏状态,$e_i$是字符$x_i$的输入嵌入。矫正网络的最后一层利用softmax函数,从候选列表中选择概率最大的字符作为字符$x_i$的输出。
2.5 Learning
只要对BERT进行预训练并给出原始序列-纠正序列这种序列对后,就可以实现端对端地软掩膜BERT学习。训练对记为${(X_1,Y_1),(X_2,Y_2),…,(X_n,Y_n)}$。
创建训练数据的一种方法是使用混淆集添加错误。
学习过程通过优化两个目标来驱动,这两个目标分别对应错误检测和错误矫正:
${L}_{d}$是检测网络的训练目标,${L}_{c}$是矫正网络训练的目标。这两个目标线性组合一起成为总目标。
3 Experimental Results
3.1 Datasets
基础数据集使用了SIGHAN。
除此之外,在今日头条上采集了新闻标题,进行了添加错误,错误的概率比较高。三人进行了五轮标记,以仔细纠正标题中的拼写错误。数据集包含15,730个文本。共有5,423个包含错误的文本,共3,441种类型。我们将数据分为测试集和开发集,每个测试集包含7,865文本。
此外,还有自动生成的错误数据,约500万个新闻标题。将文中15%的文本替换为其他字符,其中80%是混淆集中的谐音字符,20%随机字符。
3.2 Baseline
NTOU:一种使用n-gram和规则的分类器的方法
NCUT-NTUT:词向量和crf的方法
Hanspeller++:HMM、过滤去和重排的方法
Hybrid:数据增强和BiLSTM
Confusionset:seq2seq、指针网络、复制机制
Faspell:seq2seq ,采用bert作为降噪自动编码和解码器
BERTPretrain:预训练BERT
BERT-Finetune:微调BERT
3.3 Experiment Setting
句子级别的准确率、精确率、召回率、F1。
3.4 Main Result
3.5 Effect of Hyper Parameter
使用的训练数据越多,性能就越高。还可以观察到,软掩膜BERT始终优于BERT-Finetune。
3.6 Ablation Study
3.7 Discussions
与BERT-Finetune相比,Soft-Masked BERT能够更有效地使用全局上下文信息。通过软掩蔽,可以识别可能的错误,因此,该模型可以更好地利用BERT的功能,不仅可以引用局部上下文,还可以引用全局上下文,从而对错误进行合理的推理。
4 Related Works
5 Conclusion
我们称为软掩膜BERT的模型由检测网络和基于BERT的校正网络组成。检测网络识别给定句子中可能不正确的字符并对其进行软掩盖。校正网络以软掩蔽字符为输入,并对字符进行校正。软掩膜技术是通用的,在其他检测校正任务中可能很有用。在两个数据集上的实验结果表明,软掩膜BERT明显优于仅使用BERT的最新方法。在将来的工作中,我们计划将软掩膜BERT扩展到其他问题,例如语法错误纠正,并探索实现检测网络的其他可能性。